- A+
一、为何需要实时库存预警看板?
在瞬息万变的市场环境中,库存管理已不再是简单的仓储与记账,而是决定企业现金流、客户满意度与核心竞争力的关键环节。传统的依赖人工盘点或周期性报表的管理模式,因其固有的滞后性,已无法满足现代商业的敏捷性要求。实时库存预警看板,正是应对这一挑战的利器,它能将被动的事后处理转变为主动的事前干预,成为企业精细化运营的神经中枢。
1. 规避资金断流与超储风险,实现精益化管理
库存持有成本与缺货损失是企业运营中一对永恒的矛盾。实时库存预警看板通过量化指标,为这对矛盾的平衡提供了精确的导航。一方面,它能实时监控库存水位,当库存低于设定的安全阈值时,系统会立即触发低库存预警。这使得采购部门能提前获知补货需求,避免因生产原料或畅销商品断货导致生产线停工、销售机会流失,从而保障了业务的连续性与客户满意度。另一方面,当库存因预测失误或订单变更而积压,超过预设的最高库存线时,看板会发出高库存警报。这促使管理层及时采取促销、调拨或停止采购等措施,加速资金周转,降低仓储、维护及商品贬值带来的巨大成本。通过这种双向预警机制,企业得以将库存维持在最佳水平,最大限度地释放了被占用的流动资金,实现了真正的精益化管理。
2. 提升跨部门协同效率,驱动数据化决策
库存问题本质上是企业内部信息流不畅的体现。实时库存预警看板打破了部门间的信息孤岛,构建了一个透明、共享的数据协同平台。采购、销售、仓储、财务等部门无需再通过繁琐的邮件沟通或会议来同步库存状态,所有人都能在同一看板上看到即时、准确的数据。销售部门可以基于实时库存做出更精准的交付承诺;采购部门能根据动态消耗趋势制定更科学的采购计划;财务部门则能清晰地预判未来的资金占用情况。这种透明化机制不仅减少了内耗与沟通成本,更将决策模式从“凭经验”升级为“看数据”。面对突发的市场需求波动,管理层可以依据看板提供的数据洞察,快速反应,果断决策,确保整个供应链体系的高效协同与敏捷响应。
3. 赋能供应链全局优化,增强市场竞争力
库存是供应链健康状况的晴雨表。一个孤立的库存预警只能解决局部问题,而一个集成的实时库存预警看板则能赋能整个供应链网络的优化。当看板数据与供应商系统、物流平台乃至客户需求数据打通后,其价值将呈指数级增长。例如,通过长期分析预警数据,企业可以识别出哪些供应商的交付周期不稳定,从而优化供应商选择;可以发现哪些区域的仓库周转率低下,进而调整仓储布局;甚至可以预测季节性需求变化,提前做好全局库存部署。这种基于真实数据的深度洞察,使企业能够从被动响应市场,转变为主动预测和引导市场,在降低运营风险的同时,以更快的响应速度和更稳定的交付能力,构筑起难以逾越的竞争壁垒。
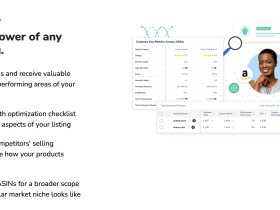
二、Helium 10 数据导出的核心步骤

1. 确定导出目标与数据范围
在Helium 10中导出数据前,需明确分析目标。例如,若需分析竞品关键词表现,应从Xray工具导出关键词排名数据;若需监控库存趋势,则需从Inventory Alerts模块导出库存报告。操作时,先进入对应工具界面,设置筛选条件(如时间范围、ASIN或关键词),确保导出的数据与需求匹配。注意,部分工具(如Keyword Tracker)支持按日/周/月粒度导出,需根据分析周期调整参数,避免冗余数据影响效率。
2. 执行导出操作与格式选择
Helium 10提供多种导出方式。以Xray为例,在搜索结果页点击“Export”按钮后,可选择CSV或Excel格式。CSV适合快速导入数据分析工具,而Excel格式保留可视化图表,适合直接生成报告。对于大型数据集(如超过10万条关键词),建议分批导出或使用“Scheduled Reports”功能定时生成。导出时需勾选“Include Hidden Columns”以确保完整数据,部分工具(如Market Tracker)还支持自定义导出字段,如价格、评分等。

3. 数据清洗与验证
导出后的数据可能存在格式不一致或缺失值。需使用Excel或Python脚本清洗数据:删除重复行、标准化日期格式(如统一为YYYY-MM-DD)、填充空值(如用“N/A”替代)。同时,验证关键指标:Xray导出的销量数据应与亚马逊后台库存报告交叉核对,确保误差率在5%以内。若导出关键词数据,需检查搜索量与排名的合理性,剔除异常值(如搜索量为0但排名前10的关键词)。
合理利用Helium 10的导出功能,能显著提升数据驱动决策的效率。关键在于精准定位需求、规范操作流程,并严格把控数据质量,从而为选品、定价或广告策略提供可靠依据。
三、Google Sheets 接收数据的准备工作
1. 创建与配置目标工作表
首先,需在 Google Sheets 中新建或选择一个现有工作表作为数据接收端。关键步骤包括:
1. 命名规范:为工作表及标签页设置清晰名称(如“客户反馈”“销售数据”),便于后续识别与自动化处理。
2. 列标题标准化:第一行需定义列标题,确保与数据源字段一一对应(如“日期”“姓名”“订单号”)。避免特殊字符或空格,建议使用下划线连接(如“订单状态”)。
3. 数据格式预设:选中列并设置格式(数字、文本、日期等),例如“金额”列设为货币格式,“日期”列设为 YYYY-MM-DD 格式,防止数据错乱。
4. 权限管理:点击“共享”按钮,设置编辑权限。若需通过 API 访问,需生成服务账号密钥(详见下文)。

2. 启用 API 与获取凭证
Google Sheets 需通过 API 接收外部数据,需完成以下配置:
1. 开启 Google Sheets API:
- 访问 Google Cloud Console,创建新项目或选择现有项目。
- 在“API 和服务”中搜索并启用“Google Sheets API”。
2. 创建服务账号:
- 转到“凭据”页面,选择“创建凭据” > “服务账号”。
- 填写服务账号名称,生成 JSON 密钥文件并下载。此文件包含认证信息,需妥善保管。
3. 授权访问:
- 在 Google Sheets 中,将服务账号邮箱(格式:[email protected])添加为共享编辑者。
- 若使用 OAuth2.0,需配置重定向 URI 并获取客户端 ID 与密钥。
3. 编写自动化脚本(可选)
为动态写入数据,可结合 Google Apps Script 或第三方工具:
1. Apps Script 方案:
- 在工作表中点击“扩展” > “Apps Script”,编写函数接收 POST 请求。示例代码片段:
function doPost(e) {
const sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("数据");
const data = JSON.parse(e.postData.contents);
sheet.appendRow([data.date, data.name, data.value]);
return ContentService.createTextOutput("Success");
}
- 部署为 Web 应用,设置“任何人,甚至匿名用户”可访问。
- 第三方集成:
- 使用 Zapier 或 Make(原 Integromat)等工具,将数据源(如表单、数据库)与 Google Sheets 绑定,配置触发条件与字段映射。
通过以上步骤,工作表即可稳定接收结构化数据。测试时建议用少量样本验证字段匹配与格式正确性,避免全量数据导入时出错。
四、设置自动化数据同步脚本
1. 需求分析与脚本选型
在构建自动化数据同步方案前,需明确数据源类型(如数据库、API、本地文件)、同步频率(实时/定时)及目标系统兼容性。针对结构化数据,Python的pandas结合SQLAlchemy或requests库可高效处理多源数据;对于实时性要求高的场景,可考虑Apache Airflow或Kafka Connect。需优先评估脚本的容错能力(如网络中断重试机制)和日志记录功能,确保异常可追溯。例如,若同步MySQL数据库至Elasticsearch,可选用Logstash或自建Python脚本,后者在轻量化场景中更具灵活性。
2. 核心脚本逻辑实现
以Python为例,实现MySQL到CSV的定时同步脚本需包含以下模块:
1. 数据抽取:使用pymysql连接数据库,通过pd.read_sql()执行增量查询(如基于时间戳字段updated_at)。
2. 数据清洗:调用pandas的.drop_duplicates()和.fillna()处理重复值与缺失值,确保数据一致性。
3. 写入目标:利用to_csv()导出文件,若需上传至云存储,可集成boto3(AWS S3)或oss2(阿里云OSS)的SDK。
示例代码片段:
import pandas as pd
from pymysql import connect
from datetime import datetime
def sync_data():
conn = connect(host='db_host', user='user', password='pwd', database='db')
query = "SELECT * FROM orders WHERE updated_at > %s"
df = pd.read_sql(query, conn, params=[last_sync_time])
df.to_csv(f"sync_{datetime.now().strftime('%Y%m%d')}.csv", index=False)

3. 调度部署与监控优化
将脚本部署为定时任务可通过Linux的cron或云服务商的调度服务(如AWS Lambda + EventBridge)。cron配置示例:
0 2 * * * /usr/bin/python3 /path/to/script.py >> /var/log/sync.log 2>&1
需设置日志轮转(如logrotate)防止日志文件过大。监控方面,可集成Sentry捕获异常,或通过SMTP发送失败告警。对于大规模数据,应将脚本容器化(Docker)并使用Kubernetes CronJob管理资源,同时添加分页查询(LIMIT/OFFSET)或流式处理(chunksize参数)避免内存溢出。性能优化可考虑并行处理(multiprocessing)或数据库读写分离策略。
五、库存预警逻辑的构建方法
1. 明确预警阈值设定原则
库存预警的核心在于科学设定阈值,需结合业务特性与数据分析动态调整。首先,区分关键物料与普通物料:对A类物料(高价值、低周转)采用紧缩阈值,如安全库存覆盖7天需求;对C类物料(低价值、高周转)可放宽至15天。其次,引入波动系数模型,通过历史销量标准差计算动态阈值,公式可简化为:预警阈值 = 平均日销量 × (1 + 波动系数) × 采购周期。例如,某商品日均销量100件,波动系数0.2,采购周期10天,则阈值应为1200件。最后,需设置分级预警机制:黄色预警(库存<阈值×1.2)、红色预警(库存<阈值),并绑定不同响应流程,如黄色触发补货提醒,红色启动紧急采购。

2. 建立多维度监控指标体系
单一库存数量预警易忽略场景复杂性,需构建多维指标矩阵。第一维度是时间维度:监控库龄结构,对超过90天的呆滞库存触发预警,避免资金占用;同时引入前置时间预警,当供应商交付延迟概率>20%时自动升级。第二维度是流程维度:设置在途库存与可用库存双指标,例如当在途库存占比>总库存50%时,提示供应链风险;同时关联销售预测,当预计未来7天销量>可用库存120%时触发补货信号。第三维度是成本维度:结合库存持有成本与缺货损失,通过边际分析法确定最优预警点,如某商品缺货损失是持有成本的3倍,则阈值需上浮30%以平衡风险。
3. 实现预警响应的自动化闭环
预警的价值在于快速响应,需通过系统工具实现闭环管理。首先,搭建规则引擎,将预警条件转化为可执行指令,例如当红色预警触发时,系统自动生成采购订单并推送至审批流。其次,集成外部数据源,如天气预警、促销计划等,动态调整预警策略(如促销前3天自动下调阈值20%)。最后,建立预警效果评估机制,通过复盘误报率(如<5%)与响应时效(如2小时内处理率>90%)持续优化算法。例如,某企业通过分析发现季节性商品预警滞后,遂在模型中加入温度参数,使预测准确率提升至92%。
六、看板可视化设计的关键要素
1. 目标导向:以行动而非信息为中心
看板的核心价值在于驱动行动,而非单纯陈列信息。设计前必须明确:谁使用这个看板?他们需要依据信息做出什么决策?例如,生产车间看板需突出异常工位与产能缺口,帮助班组长实时调度;销售看板应聚焦线索转化率与客户分层,指导销售优先级分配。
目标导向设计需遵循“3秒法则”:关键指标应在3秒内被捕捉。这要求将核心数据置于视觉黄金区域(屏幕上半部或左上角),并用动态对比(如颜色、箭头)强化变化趋势。例如,库存看板用红色预警低库存物料,绿色标识安全库存,避免用户逐行扫描。同时,需剥离冗余数据——若用户无法通过某指标直接关联到具体行动(如调整排班、联系供应商),则应考虑删除或折叠。
2. 视觉层次:构建数据的信息优先级
人类视觉系统天然遵循“从整体到局部”的认知规律,看板设计需通过视觉层次引导注意力。首先建立主次分组,将同类指标用边框或底色聚合,如财务看板中“收入”“成本”“利润”形成独立模块,避免信息碎片化。其次,利用视觉权重区分优先级:核心数据用更大字号(如24pt以上)、更鲜艳颜色(如橙色),辅助信息则用灰色小字号(如12pt)。
动效是强化层次的隐性工具。例如,当生产效率低于阈值时,相关模块可添加脉冲闪烁;实时更新的数据(如订单成交额)用数字滚动效果,增强“即时性”感知。但需警惕过度设计——动效应服务于信息传递,而非干扰。静态元素中,留白是关键分隔符,模块间距至少保持10-15像素,避免视觉拥挤导致认知负荷。

3. 反馈闭环:从可视化到决策优化的迭代
看板不是静态展示工具,而是持续优化的反馈系统。设计时需内置“数据-行动-结果”闭环:每个关键指标旁应标注责任人(如“采购部-张三”)和行动按钮(如“发起补货”),推动数据直接转化为执行动作。例如,设备故障率看板中,异常数据旁可链接故障报修系统,点击即可生成工单。
定期验证看板有效性至关重要。通过用户行为分析(如热力图)识别高频关注区域,淘汰无人问津的指标;每月收集使用反馈,调整数据计算逻辑(如将“平均响应时长”改为“超时响应率”以更直观反映问题)。最终目标是让看板随着业务迭代而进化,始终与决策需求保持同频。
七、预警通知机制的实现方式
预警通知机制是保障系统稳定性和业务连续性的关键环节,其核心在于将潜在的或已发生的异常事件,以最高效、最可靠的方式传递给正确的处理人。一个完善的预警系统并非简单的消息推送,而是集成了事件检测、规则判断、多路分发与状态跟踪的综合性闭环解决方案。
1. 基于规则引擎的实时分级分发
实现预警的第一步是建立灵活且强大的规则引擎。该引擎负责接收来自监控系统、应用日志或数据库的原始事件数据,并根据预设的阈值、模式或算法进行实时分析。例如,当服务器CPU使用率连续5分钟超过90%,或API错误率在1分钟内突增50%时,规则引擎即判定为预警事件。
事件的分级分发是关键。系统需根据事件的严重性(如紧急、重要、一般)、业务影响范围和所属服务模块,动态匹配不同的通知策略。紧急事件(如核心服务宕机)应立即通过电话、短信等高权重渠道触达负责人及多级备份人员;重要事件(如队列积压)可通过即时通讯工具(如钉钉、企业微信)发送;一般事件(如非核心功能异常)则可聚合为邮件日报或周报。这种分级机制确保了关键信息不被淹没,同时避免了无效报警对团队的干扰,实现了警情的精准触达。

2. 多通道融合与智能降噪策略
为确保信息传递的可靠性,单一通知渠道存在风险。因此,构建多通道融合的通知体系至关重要。系统应集成电话、短信、邮件、即时通讯工具(IM)、移动端推送等多种渠道,并设定通道优先级和升级策略。当首选渠道(如IM)在指定时间内未被确认接收时,系统应自动切换至次级渠道(如短信),实现“找不到人就打电话”的强制保障。
然而,过多的报警会引发“报警疲劳”,导致关键响应延迟。为此,必须引入智能降噪策略。这包括:1)报警收敛:将短时间内由同一根源引发的大量报警聚合成一条,附带关键上下文信息;2)静默期设置:对已知问题或维护窗口期的报警进行临时抑制;3)依赖关系分析:识别出报警事件的上下游依赖,避免重复通知,例如,当物理服务器故障时,只需上报服务器级报警,而自动停止其上所有虚拟机服务的报警。通过这些策略,系统能大幅提升报警的信噪比,让运维团队聚焦于真正需要解决的问题。
八、测试与优化自动化流程
1. 单元测试与集成测试
为确保自动化流程的可靠性与稳定性,必须执行严格的测试策略。首先,通过单元测试对流程中的最小可执行单元(如单个函数或模块)进行独立验证。例如,在数据处理流程中,需测试数据清洗脚本能否正确处理空值、重复数据及异常格式。测试用例应覆盖正常场景与边界条件,如输入空列表或超长字符串时的行为。
集成测试则聚焦于模块间的协作。当多个组件(如数据采集、存储与分析模块)协同工作时,需验证数据传递的准确性与时序逻辑。例如,测试API调用与数据库写入的同步性,确保数据在传输过程中无丢失或错位。使用模拟环境(Mock Server)替代外部依赖,可隔离测试范围,提升效率。测试结果需记录详细日志,便于追踪失败原因。

2. 性能测试与瓶颈优化
自动化流程的高效性是核心目标,需通过性能测试识别瓶颈。负载测试模拟高并发场景,例如批量处理10万条数据时的响应时间与资源占用。压力测试则逐步增加负载,直至系统崩溃,以确定其最大承载能力。工具如JMeter或Locust可模拟多线程请求,监控CPU、内存及I/O指标。
瓶颈优化需基于测试数据针对性改进。若数据库查询耗时过长,可通过索引优化或分库分表提升速度;若脚本执行效率低,需重构算法(如用Pandas替代循环操作)。缓存策略(如Redis缓存频繁访问的数据)能显著减少重复计算。优化后需重新测试,确保性能提升未引入新问题。
3. 持续监控与迭代改进
自动化流程上线后,需建立持续监控机制。通过日志分析工具(如ELK Stack)实时收集错误日志和性能数据,设置阈值告警(如CPU使用率超80%时触发通知)。监控指标包括任务成功率、平均执行时间及错误频率。例如,若某步骤失败率突增,需立即排查上游数据源或依赖服务变更。
迭代改进基于监控反馈与业务需求变化。定期评估流程的冗余性,合并或移除低效步骤。引入A/B测试验证优化效果,如对比不同算法模型的处理精度。用户反馈同样关键,若流程输出结果不符合预期,需调整逻辑或增强容错机制。通过小步快跑的持续优化,确保流程长期稳定且适应业务演进。
九、常见问题及解决方案

1. 连接失败与设备无法识别
设备连接失败或无法被系统识别是用户最常遇到的问题之一。首先,检查物理连接是否稳固,包括线缆是否插好、接口是否损坏。若使用无线连接,需确认设备与路由器距离是否在有效范围内,并排除信号干扰。其次,更新驱动程序或固件,过时的驱动常导致兼容性问题。对于移动设备,尝试重启蓝牙或重置网络设置。若问题持续,可通过设备管理器查看硬件状态,黄色感叹号通常表示驱动故障,此时需卸载后重新安装。部分设备需专用软件或调试模式,需查阅手册确认操作步骤。
2. 性能下降与运行卡顿
系统或软件性能下降可能由多种因素引发。首先,检查资源占用情况,通过任务管理器或活动监视器定位高消耗进程,关闭非必要应用。内存或存储空间不足时,需清理缓存、删除冗余文件,或扩展硬件容量。病毒或恶意软件也会拖慢系统,定期运行安全扫描至关重要。此外,过热可能导致降频,确保设备散热良好,清理风扇灰尘或更换导热硅脂。对于特定软件卡顿,尝试清除配置文件或重置至默认设置,若问题仍存在,考虑版本回退或寻找替代工具。
3. 数据丢失与恢复方法
意外删除或格式化导致的数据丢失需冷静处理。首先,停止对相关存储设备的读写操作,避免新数据覆盖原有文件。若使用云同步,检查回收站或版本历史记录。本地恢复可借助专业工具如Recuva、EaseUS,扫描并预览可恢复文件。重要数据建议定期备份至多个位置(如外部硬盘或NAS),采用3-2-1原则(3份副本、2种介质、1份异地)。若物理损坏(如硬盘异响),应立即断电并寻求专业数据恢复服务,自行拆解可能加剧损坏。
十、进阶功能:多店铺数据整合
在电商生态日益复杂的今天,多平台、多店铺运营已成为品牌扩大市场覆盖、分散风险的核心策略。然而,数据孤岛问题也随之而来,导致商家难以获得全局业务洞察。多店铺数据整合功能,正是为了打破这一壁垒而设计。它通过统一的数据接口与标准化的处理流程,将分散在不同电商平台(如淘宝、京东、拼多多、Amazon、Shopify等)的店铺数据,包括订单、商品、库存、客户及营销数据,汇集于一个中央数据池。这不仅解决了人工登录多个后台、下载报表的繁琐操作,更为后续的深度分析与智能决策奠定了坚实、可靠的数据基础,是实现精细化运营的必要前提。
1. 自动化数据采集与标准化
多店铺数据整合的基石在于高效、精准的数据采集。该功能通过预先配置的API接口,实现对各主流电商平台数据的自动化、准实时抓取。系统根据各平台的API限制与数据结构,智能调度采集任务,确保在不影响店铺正常运营的前提下,最大化数据获取效率。采集到的原始数据格式各异,系统会立即进行标准化处理:例如,将不同平台的订单状态(如“已发货”、“Shipped”、“已送达”)统一映射为标准状态编码;将规格不一的商品属性(如颜色、尺码)归一化处理。这一过程确保了跨平台数据的一致性与可比性,为后续的聚合分析扫清了障碍,让数据真正“说同一种语言”。
2. 跨平台绩效分析与预警
当数据被有效整合与标准化后,其真正的价值在于跨平台的深度分析。商家可以在单一仪表盘内,直观对比各店铺的核心绩效指标(KPI),如销售额、利润率、转化率、客单价及广告投入产出比(ROAS)。系统能够自动生成多维度分析报告,例如,按时间维度对比各店铺的增长趋势,或按商品维度分析其在不同平台的市场表现。更进一步,集成的预警机制允许用户自定义关键指标的阈值(如库存低于安全线、差评率突增、广告花费超预算等),一旦触发,系统将立即通过站内信、邮件或短信等方式发送警报。这使得管理者能第一时间察觉异常,从被动应对转变为主动干预,有效规避潜在风险,抓住转瞬即逝的商机。