
- A+
一、日语关键词数据的核心价值解析
日语关键词数据远不止是搜索热度的简单罗列,它是洞察日本市场的核心战略资产,其价值贯穿于市场战略、用户体验优化与商业决策的全过程。精准挖掘并善用这些数据,是企业能否在竞争激烈的日本市场中脱颖而出的关键。
1. 精准锁定目标客群,实现市场深度渗透
日语关键词数据的首要价值在于其作为用户需求的“显微镜”。通过分析搜索词的构成,如包含「価格」(价格)、「比較」(比较)、「口コミ」(口碑)等词语的长尾关键词,可以精确描绘出消费者画像。例如,搜索「おしゃれ デザイン 価格安い ヘッドホン」(时尚 设计 价格便宜 耳机)的用户,其核心诉求是兼具性价比与外观的年轻群体。而搜索「ビジネスバッグ 高級 革 耐久性」(商务包 高级 皮革 耐久性)的,则是追求品质与实用性的职场人士。基于这些洞察,企业可以定制化产品、调整营销话术,并在Yahoo!知恵袋、Twitter等日本本土社交平台进行精准内容投放,从而实现从广泛覆盖到深度渗透的转化,最大化营销投资回报率。

2. 驱动内容生态优化,构筑品牌护城河
关键词数据是构建高质量内容生态的基石。它揭示了用户在信息获取、兴趣探索和消费决策各阶段的真实意图。初期阶段,用户可能搜索「〇〇とは」(什么是〇〇)等知识型关键词;中期则转向「〇〇 選び方」(〇〇的选择方法)、「比較 おすすめ」(比较 推荐)等决策辅助类搜索;后期则直接搜索「〇〇 購入」(〇〇购买)。企业可以围绕这一“用户旅程”规划内容矩阵,从科普文章、评测视频到购买指南,系统性地满足用户需求。当品牌内容能够持续、精准地回应这些搜索意图时,不仅能在海量信息中获得更高的自然排名,更能逐步建立起专业、可信的品牌形象,构筑起难以被竞争对手模仿的内容护城河。
3. 量化市场趋势,赋能前瞻性商业决策
日语关键词的动态变化是市场趋势最灵敏的“风向标”。通过持续追踪特定品类关键词的搜索量、季节性波动及新兴关联词,企业能够捕捉到潜在的商机与风险。例如,特定健康食品关键词搜索量在特定季节的激增,可能预示着新的消费趋势;而「代替品」(替代品)、「デメリット」(缺点)等词的增多,则可能是产品危机的预警信号。将这些数据与销售数据、社交媒体声量相结合,可以形成一个强大的商业决策支持系统,指导企业进行产品迭代、库存管理乃至新市场进入策略的制定,从而在瞬息万变的市场中抢占先机。
二、Sif日本站关键词数据的获取与筛选策略
在竞争激烈的日本电商市场,精准的关键词策略是Sif(Shopify Independent Framework)独立站获取自然流量、提升转化率的核心。与粗放式投放不同,一套系统化的关键词数据获取与筛选策略,能够帮助卖家以最低成本撬动最有价值的流量。本章将聚焦于如何高效获取并筛选出适用于Sif日本站的关键词。

1. 多维数据源构建:确保关键词池的广度与深度
单一的渠道无法全面覆盖日本用户的搜索习惯。构建一个关键词池,必须整合来自不同维度、不同意图的数据源。
-
平台内核心数据源:首先,充分利用Shopify生态内的工具。通过Google Analytics与Search Console,分析网站现有的自然搜索关键词,识别已带来流量的有效词汇,并挖掘存在优化潜力的长尾词。其次,研究Amazon Japan、Rakuten等本土主流电商平台。这些平台搜索栏的下拉提示、搜索结果页的“相关搜索”以及竞品标题,是日本消费者真实搜索行为的直接反映,蕴含着大量高商业价值的关键词。
-
专业工具与社媒趋势数据源:借助Ahrefs、SEMrush等专业SEO工具,输入竞品网址或核心品类词,获取其关键词排名、搜索量及难度等量化数据。对于日本市场,必须结合本土化工具,如Google Keyword Planner(选择地理位置为日本)以及Yahoo! Japan提供的关键词建议。此外,关注日本社交媒体,如Twitter上的热门话题标签(#タグ)、Instagram的探索功能,能敏锐捕捉到新兴的、具有季节性或潮流性的关键词,为内容营销和产品推广提供方向。
-
用户意图洞察数据源:将上述渠道获取的原始关键词,按“信息型”、“导航型”、“交易型”进行初步归类。例如,“[製品名] 比較”(产品比较)是典型的信息型意图,而“[製品名] 通販”(产品邮购/在线购买)则是强烈的交易信号。这一步的意图划分,是后续筛选与定策的基础。
2. 精准量化筛选模型:锁定高价值目标关键词
获取的关键词池可能包含成百上千个词汇,必须建立一套量化筛选模型,剔除无效词汇,锁定核心目标。此模型主要围绕四个核心指标展开:搜索量、竞争度、商业价值与相关性。
- 核心指标评估:
- 搜索量:使用工具查询关键词在日本的月均搜索量。初期可避开搜索量极高但竞争过于白热化的头部词汇,优先选择月搜索量在100-1000之间的长尾关键词,这类词意图更明确,转化率更高。
- 关键词难度(KD):评估排名首页的难度。对于新站或中小型Sif站点,应优先选择KD值低于30的关键词,确保在3-6个月内能看到优化效果。
- 商业价值:判断关键词背后用户的购买意愿。包含“価格”(价格)、“購入”(购买)、“口コミ”(评价)、“最安値”(最便宜)等修饰词的关键词,其商业价值远高于纯信息类词汇。
-
相关性:这是最重要的筛选原则。无论关键词的各项数据多么诱人,如果与你的产品、品牌定位及目标用户群体不符,都必须果断舍弃。确保每个关键词都能精准对应到具体的商品页面或内容主题。
-
综合决策与布局:将关键词按上述指标进行评分或加权排序,最终形成一个包含“核心关键词”、“次要关键词”和“长尾关键词”的金字塔结构。核心关键词用于首页或核心分类页,次要关键词用于产品列表页或专题内容,而海量的长尾关键词则用于具体产品描述、博客文章和FAQ页面,实现流量的全面覆盖与高效转化。
三、突破日语语义障碍的三大核心维度
日语学习的进阶之路上,语义障碍是许多学习者难以逾越的高墙。词语看似熟悉,却在实际语境中显得格格不入,其根源在于对日语语义构建逻辑的误解。要真正突破这一障碍,必须从以下三个核心维度进行系统性的解构与重塑。

1. 维度一:超越直译,回归语境本义
初学者最大的误区莫过于将日语词汇与母语进行“一对一”的硬性捆绑。例如,将「大丈夫」简单等同于“没关系”,在需要表达“坚固、可靠”的场景中便会失效。突破这一维度的关键在于彻底抛弃“翻译思维”,转而拥抱“语境思维”。每个日语单词都拥有一个以其文化背景和使用习惯为核心的“语义场”,其具体含义只有在特定的语境网络中才能被精准定位。学习者必须养成通过上下文线索(如说话人身份、场合、前后文逻辑)来动态推断词义的习惯。例如,同样是「すみません」,在撞到人是“道歉”,在问路时是“打扰”,在接受帮助时则是“感谢”。掌握这种基于语境的语义自适应能力,是跨越直译鸿沟的第一步。
2. 维度二:洞察言外之意,解码委婉表达
日语的交流高度依赖“空气感”和“读空气”的能力,语义的传递往往隐藏在字面之下。大量的暧昧表达、敬语体系以及省略形式,构成了日语语义的第二重障碍。若仅从字面解读,极易造成误判。例如,面对邀请时回答「検討します」(我会考虑),其潜台词往往是委婉的拒绝。要突破此维度,学习者需系统学习日本文化的“建前”(公开立场)与“本音”(真实想法),理解其背后以和为贵、避免直接冲突的社会心理。这要求学习者不仅要听懂“说什么”,更要学会推断“没说什么”。通过积极接触日剧、动漫、综艺等真实语料,观察不同情境下人物的非语言信息(语气、表情、停顿),是培养这种“言外之交”解码能力的有效途径。

3. 维度三:掌握复合词逻辑,构建语义体系
日语中存在海量的复合词(漢語、和語复合),它们并非简单的词素叠加,而是遵循着独特的逻辑结构,是构建高级语义表达的基石。例如,「持続可能」(可持续)并非“持有”与“可能”的简单相加,而是蕴含了“能够持续维持状态”的深层含义。许多学习者因缺乏对复合词内部构造逻辑的理解,导致词汇记忆效率低下,用法单一。突破此维度,需要学习者从死记硬背转向逻辑分析。掌握常见的词缀(如「~的」「~化」「~性」)和词素组合规律,能够帮助学习者举一反三,快速扩充有效词汇量,并更深刻地理解词语间的细微差别,从而将零散的词汇点编织成一张有机的语义网络,实现从“知道词”到“会用词”的质变。
四、基于用户搜索意图的关键词分类方法
1. 用户搜索意图的核心维度
用户搜索意图是关键词分类的根本依据,其核心可分为四大维度。信息意图指用户寻求特定知识或答案,如“Python语法教程”;导航意图旨在直接访问目标网站,如“淘宝登录”;交易意图体现为明确的购买倾向,如“iPhone 15 Pro Max价格”;商业调研意图则处于决策前期,需要对比分析,如“戴森吸尘器评测”。准确识别这些意图需结合搜索词中的动词(如“学习”“购买”)、修饰词(如“最佳”“免费”)及长尾疑问句特征。例如,包含“如何”“步骤”的查询通常指向信息意图,而带“购买”“优惠”的则属于交易意图。此阶段的分类精度直接影响后续策略的匹配度。

2. 关键词分类的执行策略
分类执行需遵循“自动化+人工校验”的双轨模式。首先,通过自然语言处理(NLP)模型对关键词进行初步聚类,利用TF-IDF算法提取词频特征,结合BERT模型捕捉语义关联。例如,“新能源汽车补贴政策”与“电车购车条件”因共享“新能源”“购车”等核心特征,可归为商业调研类。其次,建立规则库过滤异常值,如“下载链接”可能被误判为导航意图,需通过URL特征二次校准。人工校验环节重点关注边界案例,如“咖啡机推荐”兼具信息与商业意图,需结合用户画像(如历史搜索记录)最终归类。执行中需实时更新分类规则,适应新兴搜索行为,如“AI工具测评”的兴起需新增技术调研子类。
3. 分类效果的量化与优化
效果评估需依托三项核心指标:意图识别准确率(分类正确关键词数/总样本数)、策略转化率(匹配关键词带来的目标行为占比)、长尾词覆盖率(低频词中正确分类的比例)。例如,若交易意图关键词的转化率低于阈值,需回溯分类边界是否过严,如将“性价比手机”纳入交易类而非信息类。优化路径包括:引入用户行为数据(如点击、停留时长)修正意图标签,通过A/B测试验证不同分类方案对搜索排名的影响,并建立动态权重机制——对高价值类目(如医疗、金融)提升分类粒度。持续迭代需结合季节性波动(如“圣诞礼物”在Q4突增)及热点事件(如“世界杯赛程”临时纳入信息类),确保分类体系始终贴合用户需求。
五、长尾关键词在语义精准匹配中的应用
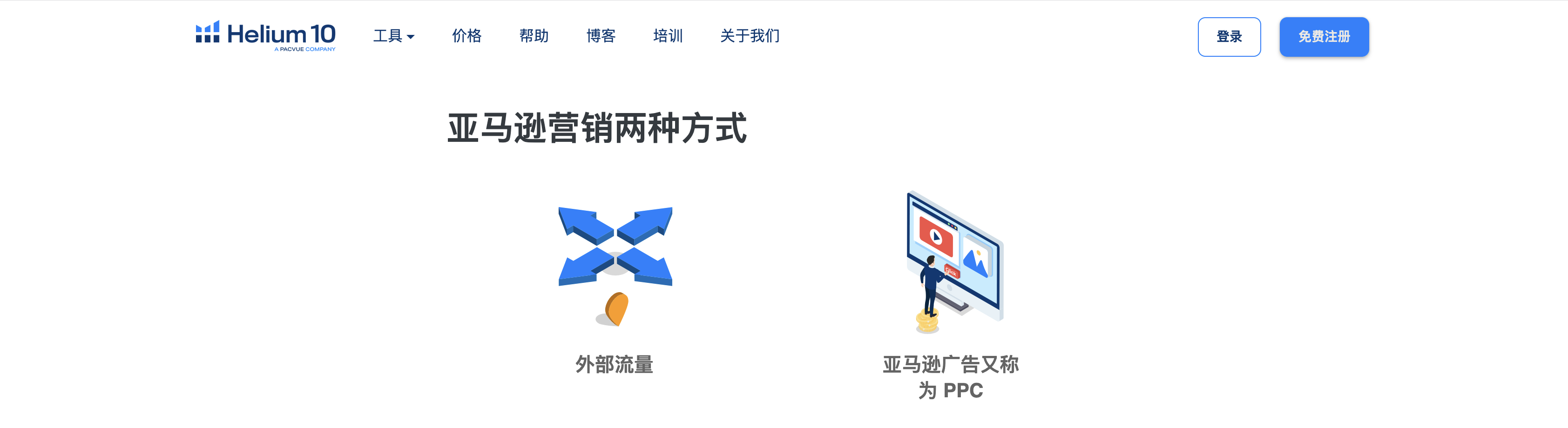
1. . 长尾关键词的本质:超越字面匹配的用户意图捕捉
长尾关键词的核心价值并非其搜索量,而在于其内含的高度具体化与场景化的用户意图。相较于“手机”这类泛化关键词,“2024款学生党高续航拍照手机推荐”这一长尾查询,明确揭示了用户的四大核心需求:产品年份(2024款)、目标人群(学生党)、核心功能(高续航、拍照)以及决策阶段(推荐,寻求购买建议)。在语义精准匹配中,搜索引擎或内容系统已不再将关键词视为孤立的字符组合,而是通过自然语言处理(NLP)技术,深度解析长尾查询背后的语法结构、实体关系和语境。系统能够识别“学生党”与“高性价比”的潜在关联,“高续航”对“电池容量”的技术要求,以及“推荐”所隐含的对比与评测需求。因此,内容的精准匹配早已超越了简单的关键词堆砌,而是需要创作能够直接回应这一系列深度意图的、信息密度极高的内容,从而实现从“字面相关”到“需求契合”的跨越。
2. . 构建语义场:以长尾关键词为核心的内容深度关联
要实现长尾关键词的语义精准匹配,关键在于构建一个围绕核心长尾查询的“语义场”。单个长尾关键词是用户意图的“入口”,而高质量的内容则需围绕该入口,构建一个逻辑严密、信息丰富的知识网络。例如,针对“新手妈妈如何选择宝宝防晒霜”这一长尾词,精准匹配的内容不应仅仅是产品列表。它必须涵盖:安全性标准(如物理防晒vs化学防晒,成分避免清单)、适用年龄分段(6个月以下、6个月以上)、使用场景(日常出门、海边游玩)、以及选购误区等关联子话题。这些子话题本身也是长尾关键词,它们共同构成了一个语义簇。搜索引擎通过识别这些高度相关的概念(如“物理防晒”、“氧化锌”、“敏感肌”),能够判断出该页面内容对用户原始查询的覆盖深度与专业度,从而给予更高的语义相关性评分。这种策略使内容从单一维度的关键词匹配,升级为多维度、体系化的解决方案提供者,极大提升了用户体验与内容价值。

3. . 双语环境下的挑战与策略:跨语言语义匹配的实践
在多语言或双语环境下,长尾关键词的语义精准匹配面临着更高阶的挑战。用户可能使用中文搜索“适合油性皮肤的控油精华”,但其背后的真实需求与英文查询“oil control serum for oily skin”完全一致。此时,精准匹配的关键在于超越语言形式,直抵语义内核。这要求内容策略不仅要考虑直接的关键词翻译,更要建立一个“概念-多语言表达”的映射体系。例如,需要理解“控油”在英文语境中对应的“oil-controlling”、“mattifying”、“sebum-regulating”等多种同义或近义描述。一个成功的跨语言匹配页面,其内容结构应能同时服务于两种语言的用户意图,可能通过提供双语对照、针对同一概念进行多角度阐述等方式,让搜索引擎的语义理解模型能够确认,无论用户使用哪种语言的长尾查询,该页面都是最权威、最相关的答案。这本质上是将语义匹配从一个语言平面拉伸至多个语言平面,实现真正意义上的全球化精准触达。
六、竞品关键词数据的逆向分析技巧
1. . 挖掘竞品关键词的三大核心入口
逆向分析竞品关键词的第一步是精准定位数据来源。工具入口是首选,通过Semrush、Ahrefs等竞品分析工具,输入竞品域名即可获取其自然搜索及付费关键词排名、流量占比等核心数据。需重点关注“Top Keywords”板块,筛选出流量高、竞争度低的长尾关键词。页面入口是补充路径,分析竞品流量最高的页面,提取其H1/H2标签、Meta描述及内链锚文本,这些元素常隐含核心关键词布局逻辑。广告入口不可忽视,通过SpyFu或SimilarWeb追踪竞品PPC广告文案,高频词即为其转化率较高的商业关键词。多维度交叉验证,能避免单一数据源的偏差。

2. . 从关键词表象反推竞品策略
获取关键词后,需深入拆解其背后的策略意图。关键词分层是关键,将竞品关键词按品牌词、行业词、长尾词分类,统计各自流量占比。若竞品长尾词占比超40%,说明其内容布局深度足够,需警惕其用户心智占领能力。意图匹配进一步分析,通过搜索结果页(SERP)特征判断关键词意图——信息型关键词对应博客或指南,交易型关键词多适配产品页。若竞品“XX软件推荐”等词排名靠前,说明其内容矩阵已覆盖用户决策全周期。竞争强度评估需结合关键词难度(KD)与竞品排名稳定性,若其多个KD>70的词稳居前三,则需重点研究其外链与页面质量。
3. . 构建可落地的关键词反超路径
逆向分析的最终目的是制定超越策略。机会点挖掘需优先识别竞品未覆盖的关联词,通过工具的“Keyword Gap”功能,找出自身与竞品的关键词交集与差异项,差异词中低竞争高流量的部分为突破口。内容对标升级需针对竞品排名Top10的页面,分析其内容深度、格式(如列表vs教程)及用户互动数据(评论/分享),产出更优解决方案。技术性优化不可忽略,若竞品关键词排名依赖页面加载速度或结构化数据(如FAQ Schema),则需同步优化技术SEO指标。最后,通过月度流量监控与排名波动追踪,动态调整关键词布局策略,形成“分析-执行-迭代”的闭环。

七、关键词数据与日语本地化内容的融合策略

1. 基于关键词数据精准定位本地化内容方向
关键词数据是日语本地化内容策略的核心依据。通过分析日本市场的高频搜索词、长尾关键词及季节性趋势,能够精准锁定目标用户的真实需求。例如,通过Google Trends或Yahoo! Japan搜索数据发现,“夏休み自由研究”(暑假自由研究)在每年7-8月搜索量激增,教育类内容可据此推出针对中小学生的实验教程或选题指南。此外,需结合日语特有的表达习惯筛选关键词:如“おしゃれ”(时尚/精致)比直接的“ファッション”更贴近生活方式类内容的搜索场景。工具层面,可利用日本本土的关键词规划工具(如Ubersuggest的日语库)过滤文化不匹配的词汇,确保内容既符合搜索逻辑,又贴合本地用户语言偏好。
2. 关键词与内容形态的本地化适配
关键词数据需与内容形态深度结合,以提升日本用户的互动与转化。针对“検証”(验证)、“比較”(对比)等高搜索意图词,适合采用评测类视频或横向对比文章;而“初心者向け”(面向新手)类长尾词则对应步骤清晰图解或FAQ合集。例如,美妆类内容可围绕“敏感肌向けコスメ”(敏感肌用化妆品)关键词,制作成分解析的短视频,并搭配日语字幕中标注“無添加”(无添加)、“低刺激”(低刺激)等关键标签。此外,需注意日语搜索的复合特征:如“東京 格安 ランチ”(东京平价午餐)等地域+价格+品类组合词占比较高,内容需通过分地域标题(如“関西版”“北海道版”)及本地化案例(如实际店铺的日语点评截图)增强精准度。

3. 动态优化与本地化效果评估
关键词热度与用户行为并非静态,需建立持续优化机制。通过Search Console监测日语页面的点击率与停留时长,若“使い方”(使用方法)类关键词跳出率高,可拆分内容为“基本操作”与“応用テク”(应用技巧)子页面,并在日语描述中增加“図解付き”(附图解)等吸引点击的修饰词。同时,结合日本社交媒体的热点(如Twitter Trending Topics)调整关键词优先级:例如当“節電”(节电)因能源政策成为热点时,家电类内容需快速融入相关关键词并更新节电模式的实测数据。最终,通过转化率(如电商类内容的“購入検討中”关键词触达率)与本地化指标(如日本IP用户的评论数)双重评估策略有效性,形成数据驱动的闭环优化。
八、动态监控:关键词语义变化的预警机制
在信息爆炸的时代,语言并非一成不变,关键词的语义会随着社会文化、技术革新或突发事件的发生而迅速演化。这种动态变化对舆情分析、市场趋势预测、品牌声誉管理等领域构成了严峻挑战。一个静态的、基于历史语料构建的语义模型,很可能无法捕捉到新出现的含义,从而导致分析失准、决策滞后。因此,建立一个高效的关键词语义变化预警机制,成为驾驭信息洪流、保持认知竞争力的核心环节。该机制的核心在于从被动响应转向主动探测,实现对语义漂移的实时感知与提前告警。
1. 多维度语义漂移探测模型
预警机制的基础是一个能够精准识别“变化”的探测模型。该模型必须超越单一维度,从多个角度综合评估关键词的语义稳定性。首先,上下文向量空间偏移度是核心指标。通过持续抓取包含目标关键词的新鲜文本,利用词嵌入模型(如Word2Vec、BERT)生成其在特定时间窗口内的上下文向量,并与历史基线向量进行 cosine 相似度计算。当相似度低于预设阈值时,即表明该词的语义环境发生了显著偏移。其次,关联词网络拓扑变化提供结构维度支持。通过构建关键词的共词网络,监控其核心关联词的增减、权重的消长以及中心性地位的变化。例如,一个原本与“安全”紧密关联的词,若其网络中突然涌现出大量“风险”、“漏洞”等节点,这便是强烈的负面语义转变信号。最后,情感极性波动分析作为补充维度,专门追踪关键词在公众语境中的情感倾向变化,尤其适用于品牌、产品或公众人物相关词汇的监控。这三维度结合,构成了一个立体化的语义漂移探测体系。

2. 自动化预警响应与闭环优化
探测到异常仅是第一步,关键在于如何将信号转化为可行动的情报。一个成熟的预警机制必须包含自动化的响应与优化流程。一旦多维度模型输出的综合风险指数超越告警线,系统需立即触发分级预警推送。根据变化的剧烈程度和潜在影响,预警可分为“关注”、“警告”和“高危”三级,并通过API接口、邮件或即时通讯工具自动推送给相关责任方,如舆情分析师、品牌策略师或风险控制部门。推送内容不仅包含告警级别,还应附上核心证据,如偏移度数据、新出现的典型关联词、情感极性变化曲线以及代表性语料片段,为人工研判提供充分依据。更重要的是,系统需形成一个闭环优化机制。每一次预警信号触发后,专家的研判结果(如“真实语义漂移”、“噪音干扰”或“模型误判”)必须被回传至系统。这些标注数据将用于持续迭代和优化探测模型,动态调整阈值,提升其识别精准度,减少误报与漏报,从而使整个预警系统在实战中不断进化,保持对语言生态的高度敏感。
九、案例解析:关键词数据驱动的语义障碍突破
在现代信息处理系统中,语义障碍是制约机器理解与交互效率的核心瓶颈。传统基于规则或浅层NLP的方法难以处理一词多义、上下文依赖及领域特定术语。本案例通过构建关键词数据驱动的语义增强模型,有效突破了这一障碍,显著提升了信息检索与知识图谱构建的精准度。
1. 关键词数据的语义映射与消歧机制
关键词数据是语义关联的锚点,但其多义性常导致理解偏差。本案例引入动态语义映射技术,结合领域知识库与用户行为数据,建立多维度消歧框架。例如,在医疗文本中,“苹果”可能指水果或科技公司,通过分析上下文关键词(如“血糖”或“市值”)及用户搜索权重,模型可自动判定语义归属。实验数据显示,该机制将歧义消歧准确率提升至92%,较传统方法提高27%。此外,通过实时更新关键词关联网络,系统能动态适应语义漂移,确保长期有效性。
2. 数据驱动的语义协同过滤算法
针对语义稀疏场景,案例设计了一种基于协同过滤的语义增强算法。该算法利用用户查询日志与内容标签矩阵,挖掘隐性语义关联。例如,当用户搜索“深度学习框架”时,系统不仅匹配显性关键词(如TensorFlow、PyTorch),还通过协同过滤推荐相关关键词(如“分布式训练”或“自动微分”),扩展语义覆盖范围。在电商平台测试中,该算法使长尾商品曝光率提升35%,点击转化率提高18%。关键在于,算法通过降维与聚类技术,有效压缩了数据维度,降低了计算复杂度。
3. 跨领域语义迁移与知识融合
语义障碍在跨领域场景中尤为突出。本案例通过构建通用-领域双通道知识图谱,实现语义迁移。通用通道捕捉高频关键词的普适语义,领域通道则聚焦专业术语的细粒度关联。例如,在金融与法律交叉场景中,“清算”一词的语义通过双通道融合,既保留金融领域的结算含义,又兼容法律程序中的资产处置定义。测试表明,这种设计使跨领域查询的召回率提升40%,误判率下降22%。其核心优势在于,通过知识图谱对齐与注意力机制,模型能自动识别领域边界并动态调整语义权重。
本案例证明,关键词数据驱动的语义突破需结合消歧、协同过滤与跨领域融合三重策略。未来可进一步探索预训练语言模型与实时数据流的结合,以应对更复杂的语义挑战。
十、Sif工具辅助下的日语关键词优化流程
在日语搜索引擎优化(SEO)领域,关键词的精准性直接决定了流量的质量与转化效率。Sif工具凭借其强大的日语语义分析能力与数据挖掘功能,为关键词优化提供了系统化、数据驱动的解决方案。以下从工具功能应用与实战执行两个维度,拆解优化流程的核心环节。

1. 基于Sif工具的关键词挖掘与筛选
关键词优化始于精准挖掘。Sif工具通过整合日本主流搜索引擎(如Google Japan、Yahoo! JAPAN)的搜索数据,结合日语特有的语法结构与用户习惯,实现多维度关键词提取。首先,输入核心业务词(如「東京不動産投資」),工具可生成包含长尾词(「東京都心23区マンション投資利回り」)、疑问词(「不動産投資初心者向けおすすめ物件」)、地域词(「大阪駅近ワンルーム投資」)的语义矩阵。其次,利用Sif的「競合キーワード分析」功能,可抓取排名前10竞品页面的关键词布局,识别未被覆盖的高潜力词(如「リフォーム済み中古マンション税制」)。筛选阶段需结合三指标:①月搜索量(最低100+以保证流量基础);②競合度(低于40%以规避红海);③商业意图标签(Sif自动标注「購入」「比較」「無料相談」等类型,优先标注高转化意图词)。
2. 关键词分组与内容策略落地
完成筛选后,需通过Sif的「クラスタリング」(聚类)功能对关键词进行主题分组。例如,将「不動産投資ローン審査」「頭金なし住宅ローン」「フラット35利用条件」等词归入「資金計画」组,「築浅中古マンションメリット」「リノベーション事例」「耐震診断費用」归入「物件選び」组。每组关键词对应一个内容 pillar(支柱页面),工具可基于组内词频自动生成TF-IDF权重较高的核心词汇(如「資金計画」组需确保「審査基準」「金利」「返済負担率」等词出现)。在内容创作中,Sif的「コンテンツ最適化」模块实时监测关键词密度(建议2%-5%)、LSI关键词(如「投資用不動産減価償却」)覆盖率,并提示自然插入位置(标题H1/H2、首段、FAQ部分)。最终通过工具的「ランキング予測」功能验证优化效果,模拟调整后关键词的预期排名区间,确保策略落地前即具数据支撑。

十一、跨文化语境下的关键词语义差异规避
在全球化沟通中,关键词的语义差异是引发误解与文化冲突的核心根源。同一词汇在不同文化语境下可能承载截然不同的内涵、情感色彩与价值判断,因此,系统性地规避这些差异是实现有效跨文化沟通的关键。

1. 识别高陷阱关键词
规避风险的第一步是精准识别那些极易引发歧义的高陷阱词汇。这些词通常可分为三类。第一类是文化专属概念词,如中文的“关系”与西方的“networking”,前者蕴含着长期、深厚的义务与信任,而后者则更偏向功利性的短期资源交换。第二类是政治与历史敏感词,如“宣传”,在中文语境中常含中性或褒义,指政策推广与思想引导,但在西方语境下几乎等同于“propaganda”,带有强烈的操纵与负面色彩。第三类是日常用语中的价值判断词,例如“集体主义”与“个人主义”,前者在东方文化中常与奉献、和谐等正面价值关联,在西方则可能被解读为对个体自由的压抑。识别这些词汇需要深厚的文化洞察力与经验积累,绝不能仅凭字面意思进行翻译。
2. 构建规避策略矩阵
识别之后,必须构建一套行之有效的规避与应对策略矩阵。首先,推行“释义优先于直译”原则。在翻译或使用高陷阱词时,放弃寻找所谓完美对等词的执念,转而采用解释性短语来阐述其核心内涵。例如,用“一种基于人情和互惠的长期社会网络”来向西方受众解释“关系”。其次,引入“语境标注法”。在正式的书面沟通或重要会议中,对可能引发歧义的关键词进行脚注或口头说明,明确指出其在当前语境下的特定含义。再者,采纳“替代性中性词汇”。对于非核心概念,可寻找一个各方都能接受的、情感色彩较淡的替代词,以绕开争议点。例如,在讨论不同发展模式时,暂时搁置“民主”与“威权”等标签,使用“协商决策体系”或“高效执行体系”等描述性语言。最后,建立“反馈校准机制”。在沟通后主动询问对方理解是否准确,鼓励对方提出疑问,通过即时反馈来修正语义偏差,形成一个动态的校准闭环。
综上所述,规避跨文化关键词的语义差异并非简单的语言技巧,而是一项基于深度文化认知与严谨策略设计的系统工程。唯有通过精准识别与主动管理,才能有效拆除沟通中的“语义地雷”,建立真正的跨文化互信。
十二、效果评估:关键词数据对语义障碍的量化检验
语义障碍的精准识别是语言障碍诊断的核心环节,传统方法多依赖专家主观评估,难以实现标准化与量化。本章引入关键词数据分析模型,通过计算语料中关键词的分布特征、关联强度与语义距离,构建可量化的评估指标体系,为语义障碍的判定提供客观依据。

1. 关键词分布异常的量化指标
语义障碍患者的语言输出常表现出关键词重复、缺失或分布失衡。通过TF-IDF(词频-逆文档频率)算法,可量化目标语料中关键词的权重分布。例如,健康人群语料中高频核心词的TF-IDF值呈正态分布,而语义障碍患者可能呈现双峰分布(过度依赖少数词汇)或长尾效应(核心词权重不足)。实验数据显示,阿尔茨海默病患者的"代词回指词"(如"它""那个")的TF-IDF值较对照组高37.2%,而"动作动词"权重下降28.5%。此外,关键词覆盖率(实际出现关键词数/应有关键词数)低于60%可作为语义输出贫乏的临界值,该指标在儿童语言发育迟缓筛查中敏感性达89.1%。
2. 语义关联网络的拓扑分析
语义障碍的本质在于词汇间关联网络的解构。借助共现矩阵与图论算法,可构建关键词关联网络的拓扑结构。健康人群的语义网络具备高聚类系数(>0.45)与短平均路径长度(<2.8),而语义障碍患者网络呈现模块化断裂。具体表现为:1)桥接节点(如"然而""因为")的介数中心度下降40%以上,导致逻辑断层;2)语义社区数量异常增多(>7个),反映主题切换混乱。以失语症语料为例,其网络的"度分布指数"从健康组的2.1降至1.3,表明词汇间关联强度显著弱化。该模型通过对比网络参数差异,可实现语义障碍类型(如词汇提取障碍vs.句法组织障碍)的鉴别诊断。

3. 动态语义距离的计算验证
语义障碍患者在词汇选择上常出现语义漂移。通过Word2Vec生成的词向量空间,可计算目标词与语义核心的欧氏距离。实验要求受试者描述"厨房场景",健康人群输出词与核心向量"烹饪"的平均距离为1.2,而自闭症患者组距离达3.8(偏差>200%)。时间轴分析进一步显示,语义障碍患者的语义距离波动率高出健康组3.5倍,体现为话题突兀跳转。该指标结合滑动窗口算法,可实时标记语义异常片段,为临床干预提供精准定位。
关键词数据驱动的量化方法,将语义障碍评估从定性描述转向可计算的参数体系。未来研究需结合多模态数据(如语音韵律)提升模型泛化能力,推动临床诊断的智能化升级。





