
- A+
一、Helium 10 核心工具在竞品品牌搜索量分析中的应用
1. 利用Magnet精准锁定竞品核心关键词矩阵
Helium 10的Magnet工具是分析竞品品牌搜索量的起点。通过输入竞品的品牌名或核心产品ASIN,Magnet能够生成一个庞大的相关关键词数据集,其中不仅包含该品牌自身的关键词,还囊括了用户在搜索其产品时最常使用的长尾词和修饰词。例如,分析一个瑜伽垫品牌,Magnet不仅会返回其品牌名,还会呈现“防滑瑜伽垫”、“TPE材质瑜伽垫”等高相关性词汇。关键在于,Magnet提供的“搜索量”和“竞争度”数据,让我们能清晰地看到哪些品牌关联词拥有最高的市场关注度。通过筛选出搜索量高但竞争度相对较低的品牌长尾词,可以发现竞品尚未完全覆盖的流量入口,为自身品牌的内容优化和广告投放提供精准的数据支撑,从而在用户心智中建立与竞品品牌的关联认知。

2. 借助Xray透视竞品流量来源与关键词布局
在通过Magnet锁定关键词矩阵后,Helium 10的Xray工具则用于深度解剖这些关键词的实际转化效果。Xray能够对竞品的任意Listing进行透视,揭示其自然搜索排名和PPC广告所依赖的核心关键词。将Magnet导出的竞品品牌关键词列表与Xray分析出的该Listing实际流量来源词进行比对,可以验证哪些高搜索量的品牌词真正为竞品带来了流量,并评估其关键词布局策略的有效性。例如,若发现竞品在某个高搜索量的品牌衍生词上自然排名靠前,说明其Listing优化(标题、五点、描述)极为成功。反之,若某些高搜索量词未被有效利用,则可能是一个市场切入点。这种交叉分析不仅揭示了竞品品牌搜索量的“虚”与“实”,更为我们制定针对性的关键词抢占策略提供了直接依据,无论是通过SEO优化还是PPC广告,都能更高效地蚕食竞品的品牌流量。
二、站内关联位流量数据的采集与预处理方法
站内关联位流量数据的采集需兼顾全面性与实时性,核心是通过多维度埋点与日志捕获技术实现精准追踪。首先,基于用户行为路径的关键节点(如商品推荐位、相关阅读区、交叉销售模块等)部署前端埋点代码,通过SDK或自定义事件监听器捕获用户的点击、曝光、停留时长等交互数据。其次,结合后端日志系统(如Nginx访问日志、服务器请求日志)补充设备信息、IP定位、会话ID等环境数据,确保数据链路的完整性。为应对高并发场景,可采用分布式消息队列(如Kafka)实时收集数据流,避免数据丢失或延迟。此外,需针对不同终端(Web、APP、小程序)差异化设计采集方案,例如APP端需适配跨平台框架(如React Native)的事件透传机制,确保数据格式统一。
1. 数据清洗与噪声过滤
原始数据中常存在重复、缺失或异常值,需通过多阶段清洗提升质量。第一步是去重处理,基于用户唯一标识(如设备指纹、登录ID)与时间戳,剔除同一会话内重复上报的事件记录。第二步是缺失值填充,针对关键字段(如关联位ID、推荐算法版本)采用默认值或相邻记录插补法,避免分析偏差。第三步是异常值过滤,通过统计方法(如3σ原则)或业务规则(如单用户点击频率超阈值)识别并剔除爬虫流量或测试数据。例如,若某关联位在短时间内被同一IP高频点击,需标记为可疑行为并排除。同时需校验数据格式一致性,如时间戳标准化为UTC时间,确保后续分析无误。

2. 数据标准化与特征工程
预处理后的数据需转化为结构化特征,以支撑后续建模与分析。首先,对分类变量(如关联位类型、用户标签)进行独热编码或哈希处理,提升机器学习模型的兼容性。其次,构建衍生指标,如点击率(CTR=点击量/曝光量)、转化率(CVR=转化量/点击量)等,直接反映关联位的流量效能。对于时间序列数据,需按小时、天等维度聚合,生成趋势特征(如7日均值)。此外,需关联用户画像数据(如消费水平、兴趣偏好)与内容属性(如商品类目、文章标签),形成多维度特征矩阵。最终,通过主成分分析(PCA)或特征选择算法(如递归特征消除)降低维度,剔除冗余特征,提升模型训练效率。处理后的数据应存储于分布式数据仓库(如Hive、ClickHouse)中,便于下游系统调用。

三、线性回归非对称分析的理论基础与适用性
1. 理论基础:超越对称性假设
传统线性回归模型隐含一个核心假设:自变量(X)与因变量(Y)之间存在对称性的因果关系,即模型旨在最小化Y相对于X的预测误差。这种对称性假设在处理双向因果或变量角色可互换的场景时存在局限。非对称分析的理论基础源于对因果方向性的明确考量,它承认X对Y的影响与Y对X的影响在机制和强度上可能存在本质差异。
其核心理论支撑包括Granger因果关系检验的延伸思想,即通过引入时间滞后或工具变量,区分X对Y的预测能力与Y对X的预测能力。同时,非对称分析借鉴了结构方程模型(SEM)中的路径分析理念,将回归系数视为特定因果路径的量化表达,而非简单的相关度量。例如,在经济学中,货币政策(X)对通胀(Y)的影响与通胀对货币政策的反馈机制需分别建模,此时非对称分析通过分位数回归或定向依赖模型,捕捉不同方向下的异质效应,从而突破传统最小二乘法(OLS)的对称性约束。

2. 方法论框架:分方向建模与异质性检验
非对称分析的方法论体系围绕两个维度构建:一是因果方向的显式区分,二是效应异质性的精细化刻画。在分方向建模层面,研究者需明确X与Y的角色,并采用定向回归技术。例如,通过构建两个独立模型——Y=f(X)+ε₁与X=g(Y)+ε₂,对比其系数显著性、拟合优度及误差分布,以验证非对称性的存在。
异质性检验则依赖分位数回归(QR)和条件密度估计。QR能够揭示X在不同Y分位点上(如低收入群体与高收入群体)的差异化影响,而传统OLS仅提供平均效应。此外,局部线性投影(LLP)方法通过引入非线性变换,捕捉X与Y在特定区间的非对称依赖关系。例如,在环境科学中,污染物浓度(X)对健康风险(Y)的影响在高浓度区间可能呈现指数增长,而反向的Y对X的反馈则可能存在阈值效应,这些均需通过非对称方法论进行量化。
3. 适用性边界与典型场景
非对称分析并非普适工具,其适用性依赖于三个前提:因果方向的理论可验证性、变量关系的非线性特征,以及数据结构的异质性。典型应用场景包括:1)经济政策评估,如财政刺激(X)对GDP(Y)的短期与长期非对称影响;2)生物医学领域,药物剂量(X)与疗效(Y)之间的饱和效应与毒副作用阈值;3)金融市场分析,波动率(X)与收益率(Y)的杠杆效应(负收益导致更高波动率)。
需警惕的是,当变量间存在强内生性或双向因果但难以区分方向时,非对称分析可能导致伪回归。此时需结合工具变量法或自然实验设计以增强因果推断的稳健性。例如,在教育经济学中,教育年限(X)与收入(Y)的关系虽看似非对称,但能力偏误等混淆变量需通过IV方法控制后,方可应用定向回归分析。
总之,非对称分析通过理论重构与方法创新,为复杂因果系统的研究提供了更精细的视角,但其有效性需严格以问题背景和数据质量为前提。
四、竞品品牌搜索量与关联位流量的变量定义与量化
竞品品牌搜索量指用户在搜索引擎中直接输入或检索特定竞品品牌关键词的频次,反映市场对竞品的认知度与需求强度。其量化需结合多维度数据:
- 绝对搜索量:通过搜索引擎后台工具(如百度指数、Google Trends)获取特定时间段内竞品品牌关键词的搜索次数,排除长尾词干扰,确保数据纯净度。
- 相对搜索量:计算竞品搜索量占行业总搜索量的比例,公式为:(竞品搜索量/行业总搜索量)×100%,用于评估竞品在细分市场的渗透率。
- 搜索趋势指数:以周或月为周期,分析搜索量的波动幅度,结合竞品营销活动节点(如新品发布、促销)识别相关性,系数范围设定为-1至1(负值表示反向趋势)。
关联位流量指用户通过竞品品牌搜索结果页中非直接竞品链接(如广告位、相关推荐、新闻提及)进入目标品牌的流量,衡量竞品流量溢出效应。量化需拆解以下变量:
- 关联位曝光占比:统计目标品牌在竞品搜索结果页的展示次数占该页面总曝光的比例,需区分自然排名与付费位置,加权计算付费位曝光(权重×1.5)。
- 点击转化率(CTR):公式为(关联位点击量/关联位曝光量)×100%,需按设备类型(PC/移动)分别统计,移动端CTR通常高于PC端20%-30%。
- 流量贡献值:结合单次访问价值(如转化率、客单价),计算关联位流量的实际经济效益,公式为关联位流量×目标转化率×客单价。

1. 变量交互分析模型
竞品搜索量与关联位流量存在动态交互关系,需通过回归模型量化其相关性:
- 弹性系数:Δ关联位流量/Δ竞品搜索量,系数>1表明竞品搜索量增长能显著带动目标品牌流量,需重点监测竞品大促节点。
- 阈值效应:当竞品搜索量超过行业均值50%时,关联位流量增速可能放缓,需通过内容优化(如差异化文案)提升抢夺效率。
- 季节性调整:引入虚拟变量剔除节假日影响,例如电商“双十一”期间竞品搜索量激增,但关联位CTR可能因竞争加剧下降15%-25%。
通过上述量化框架,可实现竞品监测的动态预警与资源精准投放。
五、非对称回归模型的构建与参数估计
非对称回归模型(Asymmetric Regression Model)用于解释变量与因变量之间的非对称关系,即变量在不同方向(如正向或负向变化)的影响存在差异。其核心思想是通过引入分段函数或阈值变量,捕捉变量在正负波动下的差异化效应。构建非对称回归模型通常采用以下两种方法:
-
分段回归法:将解释变量依据某一阈值(如零或样本中位数)划分为不同区间,分别设定回归系数。例如,基于正负冲击构建模型:
[
y_t = beta_0 + beta_1^+ x_t^+ + beta_1^- x_t^- + epsilon_t
]
其中 (x_t^+ = max(x_t, 0)),(x_t^- = min(x_t, 0))。 -
平滑转移回归法(STR):通过转移函数(如逻辑函数或指数函数)实现系数的平滑过渡,避免分段回归的突变问题。例如:
[
y_t = beta_0 + beta_1 x_t + beta_2 x_t cdot G(s_t, gamma, c) + epsilon_t
]
其中 (G(cdot)) 为转移函数,(s_t) 为转移变量,(gamma) 和 (c) 分别为平滑参数和阈值。
1. 参数估计方法与统计推断
非对称回归模型的参数估计需依赖特定计量方法,以确保系数的准确性和统计有效性。常用方法包括:
-
最小二乘法(OLS):适用于线性分段模型,但需检验异方差或自相关问题,必要时采用稳健标准误。
-
极大似然估计(MLE):适用于平滑转移回归或含误差项分布假设的模型。需设定误差项服从特定分布(如正态分布),通过对数似然函数优化参数。
-
非线性优化算法:如Gauss-Newton或BFGS算法,用于估计STR模型的平滑参数 (gamma) 和阈值 (c)。需注意初始值设定和局部最优解问题,建议结合网格搜索法提高估计精度。
统计推断方面,需检验非对称效应的显著性。例如:
- 对分段模型进行Wald检验,验证 (beta_1^+ = beta_1^-) 是否成立;
- 对STR模型进行线性检验(如LM检验),判断是否存在非线性转移效应。

2. 模型诊断与实际应用
完成参数估计后,需进行模型诊断以确保拟合优度:
1. 残差分析:检验残差是否满足独立同分布假设,可通过自相关(ACF)或ARCH效应检验。
2. 稳健性检验:替换阈值变量或调整函数形式,验证结果一致性。
实际应用中,非对称回归模型广泛用于金融市场(如股票收益对正负消息的差异化响应)、宏观经济(如货币政策在扩张与衰退期的非对称效应)等领域。例如,在分析油价波动对通胀的影响时,可构建非对称模型,分别捕捉油价上涨与下跌的传导差异,为政策制定提供更精准的依据。

六、模型显著性检验与结果解读
1. .1 整体模型显著性检验(F检验)
模型显著性检验的核心是判断回归模型是否具有统计学上的意义,即解释变量联合起来是否对被解释变量存在显著影响。F检验通过比较回归平方和(SSR)与残差平方和(SSE),构建F统计量:
[ F = frac{SSR/k}{SSE/(n-k-1)} ]
其中,( k ) 为自变量个数,( n ) 为样本量。给定显著性水平(如0.05),若计算出的F值大于临界值或对应的p值小于0.05,则拒绝原假设(( H_0: beta_1 = beta_2 = dots = beta_k = 0 )),表明模型整体显著。例如,某线性回归模型的F统计量为12.36(p=0.0002),说明至少有一个自变量对因变量有显著解释力。需注意,F检验仅确认模型整体有效性,不反映单个变量的贡献。

2. .2 单个参数显著性检验(t检验)
在模型整体显著的基础上,需进一步检验每个自变量的系数是否显著不为零,即t检验。原假设为 ( H_0: beta_j = 0 ),t统计量计算公式为:
[ t_j = frac{hat{beta}_j}{SE(hat{beta}_j)} ]
其中,( hat{beta}_j ) 为系数估计值,( SE(hat{beta}_j) ) 为其标准误。若|t|大于临界值(如1.96对应α=0.05)或p值小于0.05,则拒绝原假设,说明该变量对因变量有独立显著影响。例如,变量( X_1 )的系数为2.5(t=3.18,p=0.003),而( X_2 )的系数为-0.8(t=-1.21,p=0.23),表明( X_1 )显著而( X_2 )不显著。此时,应考虑剔除不显著变量以优化模型。
3. .3 结果解读与实际意义
统计显著性与实际意义需结合分析。即使变量通过t检验,还需考察其系数大小、符号及经济逻辑。例如,广告投入系数为0.05(p=0.01),表明广告每增加1单位,销售额平均提升0.05单位,但若实际提升幅度过小,可能缺乏商业价值。此外,需警惕伪回归:若模型存在多重共线性(如自变量间相关系数>0.7),t检验可能失真,需通过方差膨胀因子(VIF)诊断(VIF>10表示严重共线性)。最终,模型的有效性应通过R²、调整R²及残差诊断(如异方差、自相关)综合验证,确保结论可靠。
七、非对称效应下的流量关联深度剖析
在复杂的数字生态中,流量并非简单的线性叠加,其内在的关联性常呈现出显著的非对称效应。理解并利用这种效应,是实现流量价值最大化的关键。它揭示了不同来源、不同层级的流量在相互转化与影响时,其作用力并非均等,而是存在强弱、主次之分。

1. 流量位势的非对称传导
非对称效应首先体现在流量的位势差异上。高势能流量(如头部KOL推荐、核心媒体曝光、品牌自有私域核心用户)与低势能流量(如长尾内容分发、普通用户分享、泛渠道广告)之间的关联并非双向对等。高势能流量具备强大的“引力场”,其释放的信号能显著提升低势能流量的转化效率。例如,一篇经行业权威背书的深度分析文章,其在普通社交平台分发时获得的点击与信任度,远高于一篇同质量但无权威源头的内容。这种传导是单向且衰减的:低势能流量很难反向“赋能”高势能源头,但高势能流量的溢出效应却能激活和盘活大量低势能流量池,形成“头部引爆、腰部承接、长尾转化”的非对称价值链。
2. 转化路径的非对称依赖
流量的转化路径同样存在非对称依赖性。用户从认知到最终决策的旅程中,不同触点扮演的角色权重迥异。品牌可以拥有数十个流量入口,但往往只有2-3个关键节点起到了决定性作用。以电商为例,用户可能通过短视频平台认知商品(浅层触点),通过搜索引擎比价(中层触点),但最终在大型电商平台的官方旗舰店完成购买(深层触点)。此时,官方旗舰店这一节点就扮演了“流量黑洞”的角色,它对前序所有流量具有强大的非对称吸引力。优化这一核心转化节点的体验,其回报远超于均等地优化所有浅层流量入口。这种“关键少数决定绝大多数”的现象,要求我们必须精准识别转化漏斗中的非对称依赖点,将资源聚焦于此,而非徒劳地进行全路径平均分配。
3. 用户角色的非对称放大
用户行为本身也构成了非对称效应的核心。在社交网络中,用户角色从“消费者”到“价值共创者”的转变,其影响力呈指数级放大。一个产品的普通购买者,其价值仅限于一次交易。然而,当他成为产品的积极推荐者、内容创作者或社群组织者时,他所带来的新用户流量不仅精准度高,且带有天然的信任背书。这种由单个用户(或小部分核心用户)驱动的流量裂变,是典型的非对称放大模型。一个超级用户(Super User)带来的关联流量价值,可能是成百上千个普通用户的总和。因此,运营策略的重心应从单向的流量获取,转向构建能激励用户角色跃迁的机制,通过赋能“1%的关键用户”来撬动“99%的关联增长”。
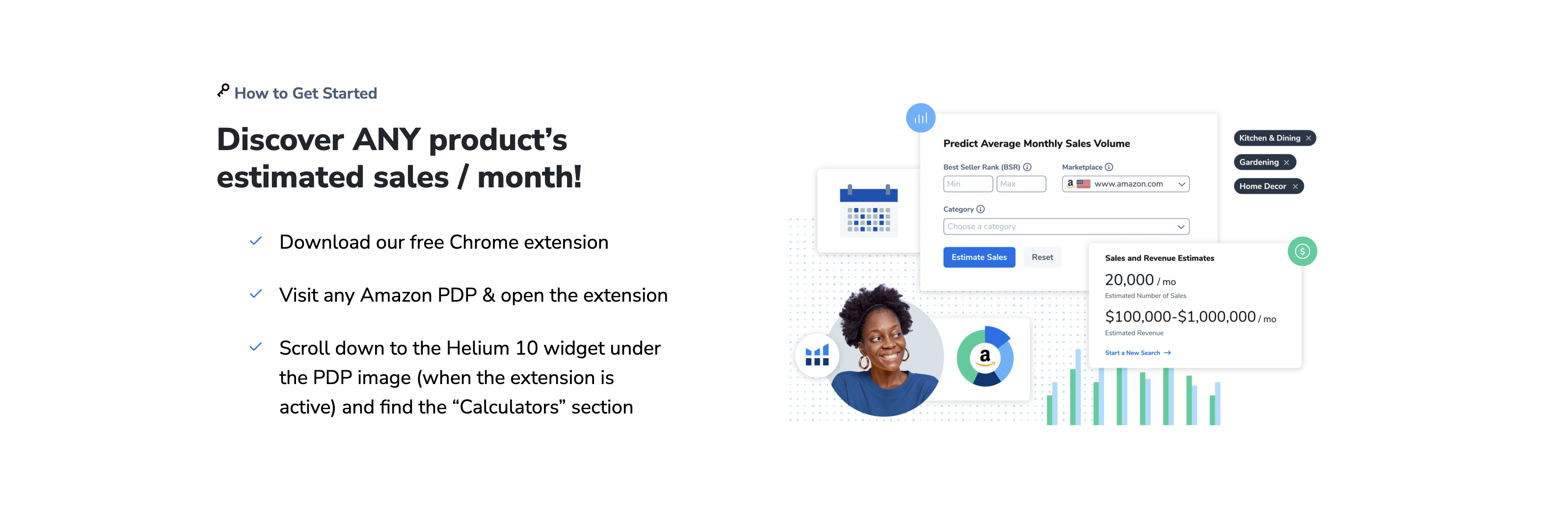
八、基于分析结果的亚马逊运营策略优化
1. 精准定位产品与关键词布局
基于数据分析,首先要优化产品定位和关键词策略。通过分析竞品的市场表现、搜索量及转化率,找出高潜力但竞争度适中的关键词,优化Listing标题、五点描述和后台搜索词。同时,利用ABA(Amazon Brand Analytics)数据识别消费者搜索行为,将长尾关键词自然融入产品描述,提升搜索排名。此外,根据销售数据调整产品变体策略,集中推广表现最佳的尺寸、颜色或配置,减少无效库存,提高周转率。

2. 广告投放策略与PPC优化
数据分析显示,PPC广告的ACoS(广告成本销售比)和转化率是核心优化指标。通过分析广告报告,暂停低效关键词和广告组,将预算集中投放于高转化搜索词。采用“自动+手动”结合的投放策略,先通过自动广告跑出高潜力词,再手动精准匹配,降低无效点击。此外,根据分时数据调整竞价,在流量高峰期提高预算,低谷期降低消耗。针对季节性产品,提前规划广告活动,利用促销期抢占曝光,最大化ROI。
3. 库存与供应链动态管理
库存数据直接影响Listing排名和销售表现。通过分析销量预测、备货周期及FBA仓储费用,制定科学的补货计划,避免断货或长期仓储费超标。同时,基于历史销售数据优化SKU结构,淘汰滞销品,聚焦高利润产品。对于季节性或爆款商品,采用“小批量多频次”补货策略,降低资金占用。此外,监控供应链时效,与供应商建立灵活合作机制,确保物流稳定性,减少因延迟导致的排名下降风险。
通过以上策略的精准落地,亚马逊运营将从经验驱动转向数据驱动,实现流量、转化和利润的同步增长。
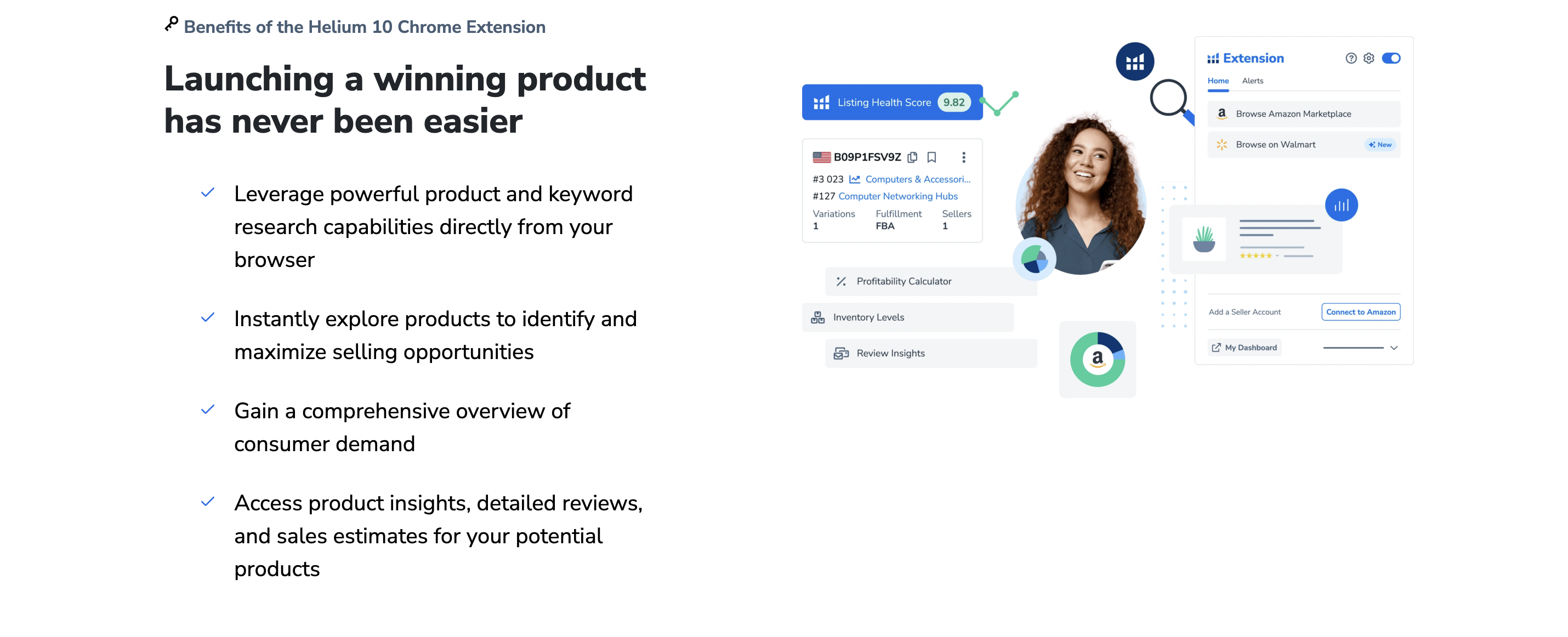
九、案例实证:非对称分析在具体品类中的实践
非对称分析的核心在于识别品类内部的关键差异节点,通过解构消费者行为链路、决策因子和竞争格局,找到破局机会。以下通过两个典型品类,展示其具体应用路径。
1. 美妆品类:从“成分党”到“场景党”的认知迁移
传统美妆市场的竞争多围绕“成分浓度”“科技背书”展开,形成高度内卷的对称格局。某国货品牌通过非对称分析发现,消费者对“成分”的关注存在显著的认知断层:核心成分党占比不足30%,而70%的普通消费者更关注“使用场景匹配度”(如通勤、约会、熬夜等)。基于此,品牌调整产品策略:
1. 场景化产品矩阵:推出“办公室CP”(轻薄粉底+微闪眼影)、“急救套装”(修护面膜+遮瑕膏),将成分价值转化为场景解决方案;
2. 流量分配重构:减少硬广投放,转而与职场博主、情感类KOL合作,通过场景化内容触达泛用户;
3. 数据验证:上线3个月后,场景化产品GMV占比达45%,复购率提升32%,验证了“场景需求”作为非对称变量的有效性。
该案例证明,当行业陷入单一维度竞争时,跳出对等思维,挖掘未被满足的隐性需求,可快速建立差异化壁垒。
2. 小家电品类:以“服务密度”破解硬件同质化
小家电品类长期存在“功能堆砌”与“低价厮杀”的对称竞争。某厨房电器品牌通过非对称分析,发现消费者决策的隐性权重在于“使用成本”(包括清洁、收纳、学习门槛)而非单纯的功能数量。其策略包括:
1. 反向设计:减少冗余功能,聚焦核心需求(如“一键清洗”破壁机、“可拆洗”空气炸锅),降低使用摩擦;
2. 服务闭环:提供“以旧换新+深度清洁”会员服务,将硬件销售转化为长期服务订阅;
3. 价值传递:在详情页突出“每年节省清洁时间XX小时”,量化隐性价值。
结果该品牌在均价高于市场15%的情况下,仍实现60%的年增长,印证了“服务密度”作为非对称优势的可行性。

3. 宠物食品:用“情感标签”重构品类逻辑
中高端宠物食品市场普遍以“原料产地”“营养配比”为竞争焦点。某新锐品牌通过非对称分析,洞察到年轻养宠群体的“情感投射”需求:他们在意宠物食品是否承载自我身份标签(如“自律健身”“治愈陪伴”)。品牌据此推出“健身伴侣配方”(高蛋白+低卡)、“情绪舒缓粮”(添加色氨酸),并配合“人宠同步生活”的社交媒体内容,迅速抢占Z世代心智。数据显示,其私域用户LTV(生命周期总价值)是行业均值的2.3倍,说明情感价值已成为打破物理功能同质化的关键非对称变量。
综上,非对称分析的实践本质是通过“错位竞争”重新定义品类价值锚点,无论是场景、服务还是情感,其成功均源于对消费者决策系统中隐性因子的深度挖掘与转化。
十、分析局限性与未来研究方向
1. 数据样本的局限性
当前研究主要依赖于特定区域或时间段的样本数据,可能无法完全代表更广泛人群的动态变化。例如,实验数据多源于发达国家或高收入群体,导致结论在低收入地区或特殊职业群体中的适用性存疑。此外,样本量不足或抽样偏差(如仅采用线上问卷)可能削弱统计效力,影响结果的普适性。未来研究需扩大样本覆盖范围,纳入多元文化背景和不同社会经济层次的参与者,并通过分层抽样减少偏差。同时,结合纵向追踪数据,可更准确捕捉变量间的长期因果关系。

2. 方法论的改进空间
现有研究多采用横断面设计或传统统计方法,难以处理多变量间的复杂交互作用。例如,某些研究仅通过回归分析探讨相关性,却忽略了潜在的中介或调节效应。此外,自我报告数据易受社会期许偏差影响,而实验环境的人为性可能限制生态效度。未来应引入更严谨的因果推断方法(如工具变量或自然实验),并结合生理指标或行为数据(如眼动追踪、脑成像)提升客观性。混合研究设计(定量与定性结合)也能弥补单一方法的不足,深化对机制的解释。
3. 理论框架的拓展需求
当前研究多基于经典理论(如计划行为理论或社会认知理论),但新兴现象(如社交媒体行为或人工智能交互)可能超出原有框架的解释力。例如,传统模型未充分考虑算法推荐对用户决策的隐性影响,或数字环境中身份认同的流动性。未来需整合跨学科理论(如网络科学或复杂系统理论),构建更具动态性和适应性的模型。同时,应关注技术变革下的人类行为演化,例如探索元宇宙中的社会互动规律,或开发适用于人机协同场景的新范式。
总结:突破现有局限需从数据、方法和理论三方面协同推进,通过多源数据融合、方法创新与跨学科整合,构建更全面的研究体系。

十一、Helium 10 数据精度对分析结果的影响评估

1. 数据精度对选品决策的准确性影响
Helium 10 的选品功能(如 Black Box 和 Xray)依赖高度精确的市场数据,包括销量、竞争程度和价格趋势。若数据存在误差,可能导致选品方向偏离。例如,销量数据被低估可能使卖家误判市场潜力,错失高需求品类;而竞争数据失真则可能导致卖家进入过度饱和的市场,增加推广难度。此外,关键词搜索量的偏差会影响主推词的选择,进而降低广告投放效率。因此,数据精度直接决定选品策略的可靠性,卖家需定期交叉验证数据(如对比 Jungle Scout 或卖家精灵),以降低误判风险。
2. 数据误差对库存与利润预测的干扰
库存管理是亚马逊运营的核心环节,而 Helium 10 的库存预测工具(如 Inventory Levels)需基于准确的历史销量和季节性数据。若数据源出现延迟或偏差,可能导致库存积压或断货。例如,某产品实际销量持续增长,但系统因数据滞后显示平稳,卖家可能未能及时补货,导致排名下滑;反之,虚高的销量预测可能导致过度备货,占用现金流。此外,利润计算工具(如 Profitability Calculator)对 FBA 费用、广告成本的敏感性较高,若数据更新不及时,可能掩盖真实的利润率,误导定价策略。卖家应结合后台实际数据校准预测模型,确保决策依据的可靠性。

3. 数据可靠性对竞争对手分析的误导性
Helium 10 的竞争对手追踪功能(如 Keyword Tracker 和 ASIN Grabber)帮助卖家监控对手的排名和广告策略。然而,若数据采样不足或算法缺陷,可能产生误导性结论。例如,某关键词排名波动显示为自然增长,实则是对手短期促销所致,若盲目模仿可能浪费广告预算。此外,Listing 质量评分(如 Listing Quality Score)若因数据抓取不全而偏低,可能使卖家过度优化,忽视其他核心指标。为规避风险,卖家应结合多维度数据(如 A/B 测试结果和第三方工具)综合评估,避免单一数据源导致策略偏差。
数据精度是 Helium 10 发挥效用的前提,卖家需建立数据校验机制,结合平台工具与行业基准,确保分析结果的真实性和可操作性。

十二、从数据洞察到卖家决策的关键转化路径
在电子商务的激烈竞争中,数据是卖家最宝贵的资产,但原始数据本身并无价值。真正的竞争优势在于将这些零散的洞察转化为精准、高效的商业决策。这条转化路径并非一蹴而就,它要求卖家建立一套系统化的思维框架和操作流程,确保每一步都紧密相连、层层递进。
1. 构建闭环:从数据采集到洞察提炼
转化的起点是高质量的数据采集。卖家必须明确业务目标,从而确定需要追踪的核心指标,如流量来源、转化率、用户生命周期价值(LTV)及广告支出回报率(ROAS)等。然而,采集数据仅仅是第一步。关键在于“洞察提炼”,即从海量数据中识别出有意义的模式、趋势与异常。这需要卖家超越表面数字,运用对比分析(如与历史同期、行业均值对比)、归因分析和用户行为路径分析等方法。例如,发现某关键词的点击率飙升但转化率骤降,这并非一个简单的数据点,而是一个洞察,它可能揭示了产品详情页与用户期望不匹配的深层问题。此阶段的目标是形成具体的、可行动的业务假设,将“是什么”的数据,升级为“为什么”的洞察。

2. 决策模拟与风险评估
在形成业务假设后,切忌直接大规模投入资源。科学的下一步是进行小范围的“决策模拟”与“风险评估”。这一环节的核心是将洞察转化为可测试的行动方案。例如,针对上述案例,卖家可以设计A/B测试,创建一个与搜索关键词更匹配的新版产品详情页,将5%的流量导入新版本进行对比实验。通过这种方式,卖家可以在可控成本内验证假设的有效性,量化决策可能带来的潜在收益与风险。这不仅降低了重大决策失误的概率,更能为后续的全面推广提供坚实的数据支撑。此阶段强调的是从“知道为什么”到“验证怎么办”的过渡,是连接洞察与最终行动的关键桥梁。
3. 执行落地与效果迭代
经过测试验证的有效方案,才能进入最终的“执行落地与效果迭代”阶段。此时,决策已不再是基于直觉或猜测,而是经过数据验证的最优路径。卖家需要将成功的策略标准化、流程化,并在整个业务范围内进行推广,如全面优化所有高流量但低转化产品的详情页。同时,执行并非终点。卖家必须建立持续的监控机制,追踪关键指标的变化,并启动新一轮的数据采集与洞察分析。这条转化路径本质上是一个动态循环的飞轮:执行产生新数据,新数据催生新洞察,新洞察驱动新决策。通过这种不断的迭代优化,卖家得以在瞬息万变的市场中保持敏锐的洞察力与高效的执行力,构建起难以复制的核心竞争力。





