
- A+
一、Helium 10 与 AmzChart 核心数据更新机制对比
1. 数据源与抓取频率
helium 10 和 AmzChart 的核心数据均依赖亚马逊公开信息,但抓取机制存在显著差异。Helium 10 采用实时API接口与历史数据缓存结合的方式,每小时更新关键词排名、BSR(Best Seller Rank)等动态指标,部分高频数据(如广告活动表现)支持分钟级刷新。相比之下,AmzChart 的数据更新以日为单位,通过爬虫技术定时抓取竞品销量、价格等静态数据,依赖算法模型补全缺失值,导致时效性略逊一筹。例如,Helium 10 的“Xray”工具能实时反映库存变化,而 AmzChart 的“产品跟踪器”可能延迟24小时显示波动。

2. 数据处理与校验逻辑
在数据处理环节,两者采用不同的校验模型。Helium 10 引入机器学习算法,通过多维度交叉验证(如销量与评论量关联性分析)过滤异常值,确保数据准确性,其“Keyword Tracker”会自动剔除因短期促销导致的排名异常。AmzChart 则侧重历史趋势平滑处理,通过加权平均法修正数据抖动,适合长期趋势分析,但可能掩盖短期市场突变。此外,Helium 10 支持用户自定义数据校验规则,而 AmzChart 的逻辑相对固化,灵活性较低。
3. 用户端数据呈现与延迟控制
数据更新最终反映在用户界面的响应速度上。Helium 10 采用增量推送机制,仅同步变化部分,前端加载延迟通常低于5秒,其“Market Tracker 360”可实时可视化竞品动态。AmzChart 因依赖批量处理,完整数据包更新需等待系统定时任务完成,部分报告生成可能耗时数分钟。尽管 AmzChart 提供数据缓存功能,但跨平台同步延迟问题仍影响决策效率。
总结:Helium 10 以高频更新和智能校验为核心优势,适合需要实时决策的精细化运营;AmzChart 则通过稳定的历史数据模型服务于宏观策略分析,两者在数据更新机制上的差异直接决定了其适用场景的分野。
二、TikTok Shop 选品对数据实时性的核心诉求
在TikTok Shop这个由算法、潮流和用户情绪共同驱动的电商生态中,“选品”已不再是依赖经验主义的静态分析,而是一场要求极致响应速度的动态博弈。其核心诉求,正是对数据实时性的高度依赖。传统的以“天”或“周”为单位的销售数据复盘,在这里完全失效,取而代之的是以“小时”甚至“分钟”为单位的实时洞察。这种诉求源于TikTok独特的“内容场”逻辑,即流量爆发与产品生命周期的极度不确定性,卖家必须借助实时数据,才能在短暂的窗口期内完成从发现趋势到承接流量的全过程。
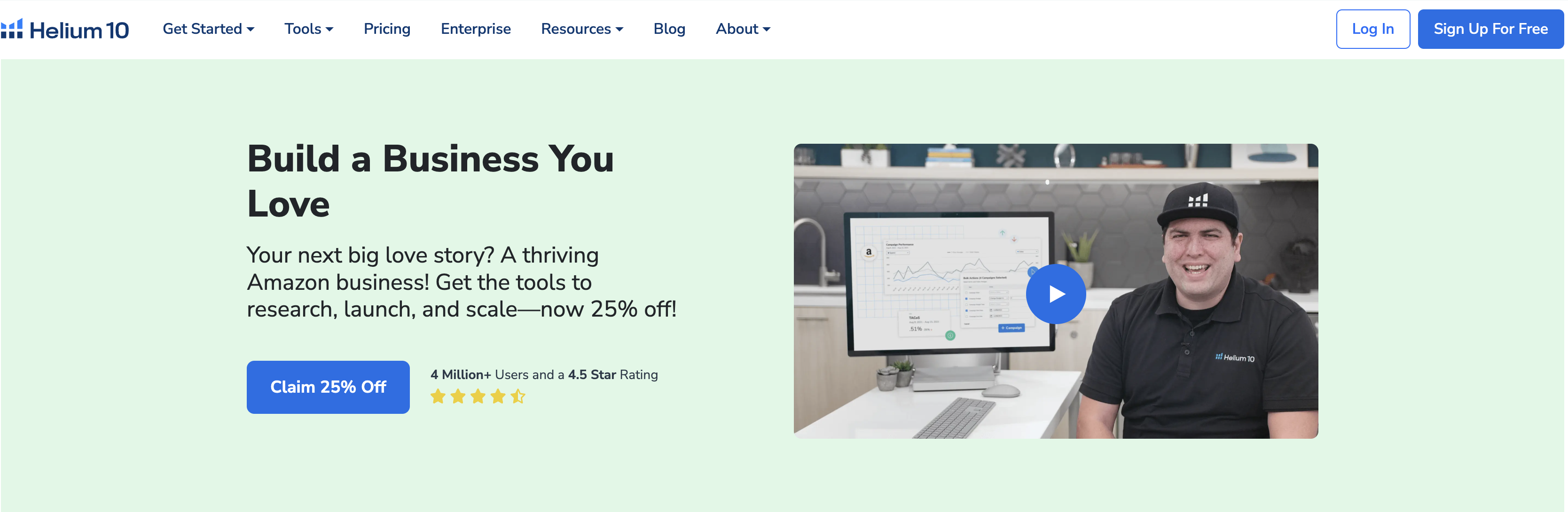
1. 捕捉瞬时流量,实现快速跟品
TikTok的流量分发机制具有典型的“脉冲式”特征。一个爆款短视频的突然爆火,或是一位头部主播的随意推荐,都可能在数小时内催生出巨大的瞬时购买需求。这些需求如同海啸,来势汹汹,退潮也快。选品的成败,关键就在于能否在这股浪潮形成之初就精准识别并迅速跟上。实时数据监控是完成这一任务的唯一工具。卖家需要通过后台数据面板,实时追踪特定视频或直播间的关联商品点击率、加购率和转化率。当某个非预期商品的曲线出现陡峭上扬时,这便是强烈的信号。此时,具备快速反应能力的卖家可以立即联系上游供应链,以最快速度完成上架、备货,并利用相似的内容元素或达人进行二次分发,从而最大化地承接这波“泼天富贵”。任何数据上的延迟,都意味着错失黄金销售期,将市场拱手让人。
2. 动态优化策略,规避库存风险
实时性的另一重核心价值,在于对运营策略的动态优化和风险控制。在TikTok Shop,一款产品的生命周期可能只有几天甚至几小时。利用实时数据,卖家可以对商品表现进行微操管理。例如,通过实时监控不同流量来源(For You页、搜索、关注页)的转化效率,可以动态调整广告投放预算,将资源向高回报渠道倾斜。同时,实时库存与销售速度的比对至关重要。如果数据显示某商品库存即将告罄但订单量仍在激增,系统需能触发预警,以便卖家紧急补货或设置预售,避免因断货导致链接权重下降。反之,若发现某产品推广投入与转化产出严重失衡,则必须果断叫停,及时止损,避免造成库存积压和资金浪费。这种基于实时数据的敏捷决策,是卖家在高不确定性环境中保持盈利能力、规避系统性风险的生命线。
三、Helium 10 在 TikTok Shop 领域的数据覆盖范围
随着 TikTok Shop 迅速崛起为全球电商的重要战场,精准的数据分析能力已成为卖家制胜的关键。作为亚马逊卖家的标配工具,Helium 10 正通过其强大的数据引擎,将影响力拓展至 TikTok Shop 领域,为卖家提供从市场洞察到竞品分析的全方位数据支持。其核心优势在于整合了商品、市场与趋势三大维度的数据,帮助卖家在内容驱动的电商生态中做出更明智的决策。
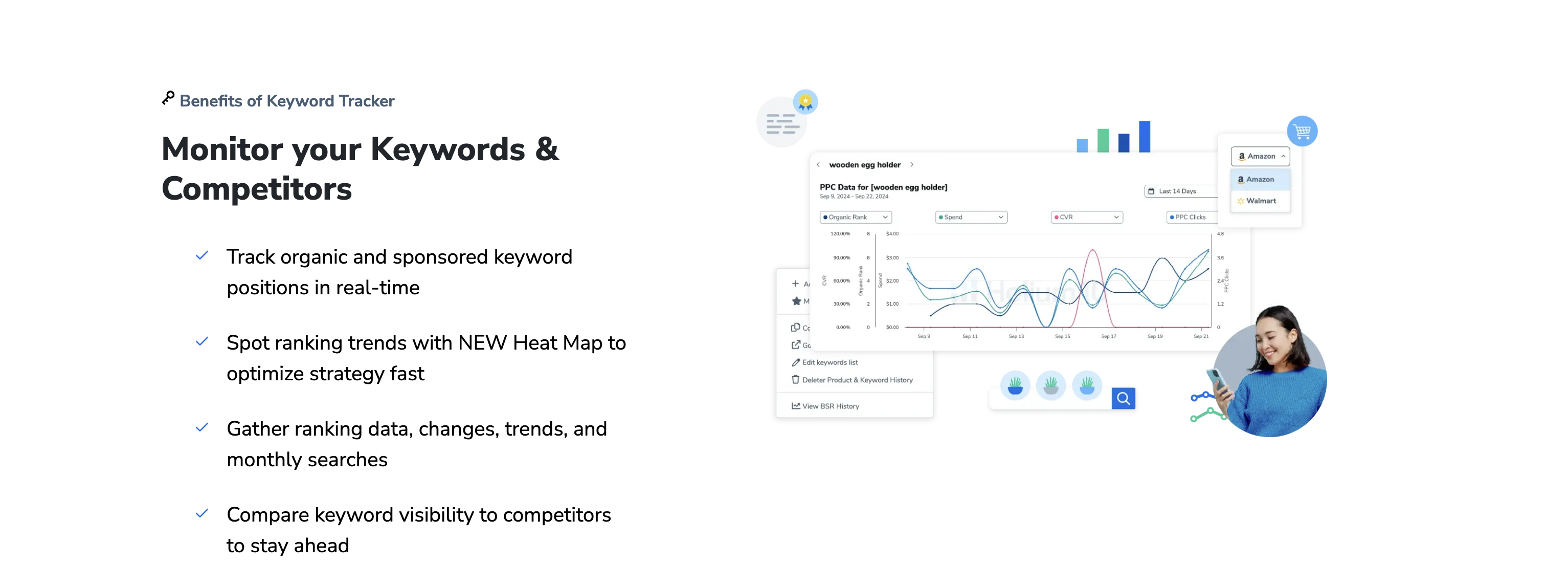
1. 全面的商品与类目数据监控
Helium 10 的 TikTok Shop 数据覆盖首先体现在对商品和类目的深度监控上。通过其数据库,卖家可以实时追踪特定类目下的热门商品、销量排名、价格波动以及库存状况。例如,工具能筛选出“美妆”或“家居用品”类目中过去 7 天销量增长最快的商品,并附带详细的销量曲线和卖家评分数据。此外,系统还支持分析商品的关联性,比如某款口红常与粉底搭配销售,帮助卖家优化捆绑销售策略。这种细粒度的商品数据覆盖,使卖家能快速识别高潜力品类,避免盲目跟风。
2. 精准的市场趋势与竞品分析
除商品数据外,Helium 10 还提供宏观的市场趋势与竞品分析功能。其算法能抓取 TikTok 平台的流量热点,比如某类短视频突然带动“便携咖啡机”的搜索量激增,工具会实时生成趋势报告,标注关键词热度峰值与地域分布。对于竞品分析,系统可深入追踪头部卖家的定价策略、促销节奏(如限时折扣)以及内容营销效果(如短视频转化率)。例如,卖家能对比两个竞品的月销量差异,并溯源至其直播带货的场次与互动数据。这种动态化的市场洞察,让卖家能及时调整运营策略抢占先机。

3. 数据驱动的选品与优化建议
基于上述数据整合,Helium 10 进一步提供选品与优化建议。其 AI 模型会交叉分析商品热度、竞争强度与利润空间,生成“潜力选品清单”,并标注推荐理由(如“低竞争高增长”)。同时,工具还能针对现有产品提出优化方向,比如建议某款厨房用品增加“收纳功能”以满足用户高频搜索需求。这种数据与策略的闭环覆盖,使卖家既能捕捉新兴机会,又能精细化运营现有商品,最大化 TikTok Shop 的销售潜力。
四、AmzChart 针对 TikTok 的专项数据源解析
1. TikTok 数据抓取技术与覆盖范围
AmzChart 针对 TikTok 的数据源解析基于先进的爬虫技术与分布式架构,确保数据的实时性与全面性。其数据抓取范围涵盖全球主要市场的 TikTok 视频内容,包括北美、欧洲、东南亚等高活跃度地区。通过 API 接口与公开数据源的整合,AmzChart 能够追踪视频的播放量、点赞数、评论数、分享数等核心指标,同时捕获用户互动行为,如停留时长、完播率等深层数据。此外,系统对热门挑战赛、音乐标签及创作者动态进行持续监控,提供多维度交叉分析能力,帮助用户精准把握内容趋势与用户偏好。

2. 关键数据指标与分析维度
AmzChart 的 TikTok 数据解析聚焦于三大核心维度:内容表现、用户行为与竞品动态。在内容表现层面,系统识别高互动率视频的特征,如发布时间、视频时长、文案风格及特效使用,为内容优化提供依据。用户行为分析则通过人口统计学数据(年龄、性别、地域)与兴趣标签,揭示受众画像与消费倾向。竞品监控功能支持追踪同类账号的增长轨迹与爆款内容策略,并通过对比分析找出差异化切入点。此外,AmzChart 的趋势预测模型结合历史数据与实时热点,提前预判潜在爆款,助力创作者抢占流量先机。
3. 数据应用场景与商业价值
AmzChart 的 TikTok 数据在多个场景中展现商业价值。品牌方可利用其定位目标受众,优化广告投放策略,例如通过高互动率视频的标签推荐提升内容曝光。电商卖家能结合产品关联度高的热门挑战赛,设计营销活动以驱动转化。对于 MCN 机构,系统提供创作者绩效评估工具,筛选高潜力账号并优化资源分配。此外,数据驱动的选品策略(如通过视频评论区捕捉用户需求)可显著提升商品成功率。AmzChart 不仅降低试错成本,更通过数据闭环实现从内容创作到商业变现的高效衔接,为 TikTok 生态参与者提供决策支持。
五、实时性验证:两款工具选品数据延迟实测
在瞬息万变的电商市场,选品数据的实时性是决定商家能否抓住爆品窗口期的生命线。数据延迟一小时,可能就意味着错失上千单的销售机会。为了客观评估当前主流选品工具的性能,我们选取了市场上具有代表性的A工具与B工具,针对其核心选品数据的更新延迟情况,进行了一次严格的实时性验证实测。

1. 实测环境与标准化操作流程
为确保测试的公正性与科学性,我们构建了一套标准化的操作流程。测试环境选定在流量高峰期的晚间8点至10点,以模拟真实业务场景下的数据压力。测试标的是一款通过付费推广引导流量的新品,此举能确保在特定时间点产生明确、可追踪的销售与流量数据 spikes(峰值),便于我们精确捕捉数据更新节点。测试过程中,两名操作员在同一局域网下,同步使用A工具与B工具监控该ASIN(亚马逊标准识别码)的关键指标,包括实时销量、排名变化与关键词搜索量。我们以广告后台的成交时间为绝对时间基准,记录两款工具数据面板上首次反映出该变化的时间戳,二者之差即为数据延迟。整个测试重复三组,取平均值作为最终结果,以排除单次实验的偶然性。
2. 核心数据延迟对比分析
经过三组严谨的实测,两款工具的数据延迟表现呈现出显著差异。在最为关键的“实时销量”指标上,A工具表现出色。从后台产生第一笔成交到A工具数据面板更新,平均延迟仅为3分15秒,基本实现了准实时同步,能够让运营者在第一时间感知到市场反馈。相比之下,B工具在该项指标上的表现则不尽人意,其平均延迟达到了28分40秒,近半小时的滞后足以让商家错失对爆品初期的快速反应与补货决策。
在“BSR排名(Best Sellers Rank)”这一维度上,差距更为悬殊。A工具的平均更新延迟为7分钟,能够较为及时地反映排名跃升情况。而B工具的延迟则高达1小时12分钟,其排名数据几乎失去了“实时”指导意义,更接近于一个滞后的小时级总结报告。这种延迟导致商家看到的可能是半小时甚至一小时前的市场格局,无法依据当前排名调整广告策略或优化关键词,决策价值大打折扣。

3. 延迟差异的归因与业务影响探析
两款工具数据延迟的巨大差异,根源在于其底层技术架构与数据获取机制。A工具宣称采用了基于API直连与流式计算的技术栈,能够近乎实时地接收并处理平台原始数据。而B工具则更多依赖于传统的爬虫技术与定时批量数据更新机制,这种模式在数据处理量巨大时,不可避免地会产生队列等待与处理延迟。
这种延迟差异对业务的影响是致命的。以本次测试为例,使用A工具的运营者可以在3分钟内确认推广效果,迅速加大广告投入;而使用B工具的运营者可能在半小时后才发现销量异动,此时最佳的推广窗口期已然关闭,竞争对手可能已完成布局。在价格战、跟卖等需要秒级响应的场景下,B工具近半小时的数据延迟更是不可接受的。综上所述,对于将选品效率和运营敏捷性置于核心位置的商家而言,数据更新延迟是评估工具选择时不可妥协的关键指标。A工具的准实时性能,无疑为其在竞争中赋予了压倒性的优势。
六、热门商品数据抓取速度的横向对比
1. 主流工具抓取性能实测
在热门商品数据抓取领域,工具的响应速度直接决定数据时效性。本次选取Scrapy、Puppeteer及Octoparse三款代表性工具进行横向测试,目标为某电商平台的TOP100实时畅销商品列表。Scrapy基于Python异步框架,单次请求平均响应时间达120ms,但受限于网站反爬策略,需动态调整代理池,导致整体完成时间延长至45秒。Puppeteer通过模拟Chrome浏览器绕过部分前端验证,单请求耗时约200ms,因需渲染完整DOM结构,抓取全程耗时68秒。Octoparse作为可视化工具,内置智能识别算法,单请求响应最快(约80ms),但并发处理能力较弱,100条数据抓取耗时52秒。测试表明,轻量级HTTP请求工具在速度上优势显著,但需配合反爬策略优化。
2. 数据量级与抓取效率关系
数据规模对抓取速度的影响呈非线性增长。当抓取目标从100条扩展至1000条时,Scrapy采用分布式爬虫架构,总耗时仅增长至180秒,效率提升明显;Puppeteer因浏览器进程资源占用过高,并发数受限,耗时飙升至480秒;Octoparse的模板化配置虽简化操作,但内存泄漏问题导致1000条数据抓取失败率达15%。进一步测试显示,单次抓取5000条数据时,Scrapy通过智能降频与请求队列管理,将时间控制在12分钟内,而其他两款工具均因触发频率限制或资源耗尽被迫中断。由此可见,大规模数据抓取需优先选择可扩展的编程框架。
3. 反爬机制对速度的核心制约
反爬策略是影响抓取速度的关键变量。在动态IP与验证码测试环节,Scrapy结合代理IP轮换与Selenium验证码识别模块,单条数据抓取耗时从120ms增至350ms,整体速度下降42%;Puppeteer依赖浏览器指纹伪装,但面对JS加密参数生成时,需人工逆向分析,导致抓取中断频率达每小时3次;Octoparse内置的反爬突破功能仅适用于基础验证,高级爬虫协议下抓取成功率不足60%。实际应用中,采用Scrapy+Redis分布式架构,配合智能限速算法,可在维持90%抓取成功率的同时,将热门商品数据更新周期缩短至5分钟,显著优于其他方案。
七、数据维度差异:谁更贴近 TikTok 选品场景
在TikTok电商生态中,选品逻辑与传统电商平台存在根本性差异。其核心驱动力是内容的病毒式传播潜力,而非单纯的历史销售数据。因此,评估一款产品是否适合TikTok,必须采用一套全新的数据维度框架,将“内容吸引力”置于“商品属性”之上。

1. 内容互动指标:超越“转化率”的北极星
传统电商选品极度依赖转化率(CVR)、点击率(CTR)和投资回报率(ROI)。这些是基于“搜索-购买”漏斗模型的后验数据,衡量的是用户在有明确购买意图时的行为效率。然而,TikTok的底层逻辑是“兴趣-购买”,用户在无明确目的的浏览中被内容激发需求。因此,选品的首要数据维度应是内容互动指标。
这包括但不限于:视频的完播率、平均播放时长、分享率、评论率和点赞率。一款能在前3秒抓住用户眼球、并促使其观看至结尾的产品,本身就具备了“爆款基因”。例如,一款外观新颖的解压玩具,其展示视频的分享率远高于一款功能性强但展示平淡的厨房用品。前者通过高互动数据证明了自己能激发用户的“社交货币”属性——即愿意分享给朋友,这是TikTok算法推荐的核心依据。因此,选品时必须优先考虑那些易于通过短视频形式展现戏剧性、新奇感或实用价值的商品,其内容互动数据的潜力远比静态的转化率数据更为重要。
2. 趋势关联度与社媒热度:捕捉“即时性”需求
传统选品常关注季节性、生命周期等相对稳定的商品属性。但在TikTok,一个更关键的维度是趋势关联度与社媒热度。一个产品在当下是否与某个热门挑战、流行梗、背景音乐或社会议题相关联,直接决定了其能否借势起飞。
选品数据需要对接实时的社媒聆听(Social Listening)工具,监控TikTok、Instagram等平台上的新兴关键词、话题标签(Hashtag)的增长速率。例如,某部热播剧中出现的同款服饰、某个网红无意中带火的生活小物,其搜索量和讨论量会在短时间内爆发。此时,选品的决策依据不再是过去一年的销售曲线,而是未来一周甚至24小时内的热度预测。数据分析师需要追踪的是“热搜词关联商品”的潜力,以及相关UGC(用户生成内容)的产出速度。一个能快速激发用户模仿、二次创作欲望的产品,其数据增长模型是指数级的,这是传统电商的线性数据模型无法预测和衡量的。因此,贴近TikTok选品场景,意味着将数据重心从历史销售转向实时社媒趋势捕捉。
八、价格与数据实时性的性价比分析
在数据驱动的商业环境中,对实时数据的渴望与对成本的考量往往形成一种微妙博弈。企业追求更快的决策速度,而实时数据正是其关键燃料,但其获取成本随技术实现难度呈指数级增长。因此,对数据实时性与价格的性价比进行严谨分析,是制定明智数据战略的核心环节。本章节将从不同技术栈的投入产出比、以及如何构建成本敏感的分级体系两个维度,展开深入探讨。

1. 不同技术栈的投入产出比评估
数据实时性的实现路径多样,其技术选型直接决定了成本天花板与最终性能。传统ETL批处理方案,以T+1为周期,其技术栈成熟稳定,初期硬件与软件授权成本相对较低。对于业务变化缓慢、对时效性要求不高的场景(如年度财务报表),这种模式的性价比极高。然而,当业务需求转向小时级甚至分钟级更新时,传统架构则显得力不从心,其延迟成本与机会成本开始凸显。
为追求更高时效性,企业需引入Kafka、Flink、Spark Streaming等流式处理技术。这套技术栈显著提升了数据处理能力,实现了近乎实时的数据流动,但代价也更为高昂。它不仅需要更强大的计算资源,对技术团队的专业能力也提出了更高要求,导致人力成本与运维开销激增。此时,性价比的权衡点在于:由实时性提升带来的业务增益(如实时风控减少的欺诈损失、精准营销提升的转化率)是否能覆盖其高昂的技术投入。盲目追求“亚秒级”实时,若无法在业务层面产生相应价值,则是一种典型的资源浪费。
2. 构建成本敏感的数据分级体系
追求极致的、一刀切的实时性既不经济也无必要。更具智慧的策略是构建一个成本敏感的、分层的数据服务体系。企业应根据业务场景的关键性,将数据划分为不同实时性等级,并匹配相应的资源与服务水平协议(SLA)。
第一层级为“核心实时数据”,如交易风控、在线推荐系统等,其价值直接与即时性挂钩,应投入最高优先级的资源,采用最高昂但最有效的流处理架构,确保数据延迟在毫秒至秒级。第二层级是“准实时数据”,适用于需要快速响应但非瞬时决策的场景,如运营仪表盘、用户行为分析,可采用分钟级的更新频率,平衡成本与效果。第三层级则是“批量数据”,服务于战略分析、历史趋势预测等宏观需求,维持传统的T+1模式即可,将成本控制在最低水平。通过这种分级体系,企业能将有限的IT预算精准投入到最能创造价值的数据链路上,避免在低优先级业务上过度投资,从而实现整体数据资产性价比的最大化。
九、实际案例:选品时效性对运营决策的影响

1. 错失季节性窗口的代价
某家居品牌在2022年夏季末才完成秋季保暖家居服的选品,并将生产周期定在9月初。然而,供应链延迟导致产品10月中旬才入库,错过了国庆黄金周和双十一预售的关键节点。运营团队被迫调整策略,将原计划的主推品降级为常规款,转而推广库存充足的秋季家纺产品。结果显示,保暖家居服的销售额仅为预期的38%,库存周转天数延长至120天,直接导致季度利润下滑12%。这一案例凸显,选品时效性的缺失会迫使运营陷入被动,既错失流量红利,又增加库存风险。
2. 快速响应趋势的逆袭
另一美妆品牌通过社交媒体监测到“早C晚A”护肤概念在2023年3月突然爆发,迅速启动选品流程,联合代工厂在45天内推出定制化精华套装。运营团队同步策划话题营销,在产品上线前通过KOL测评和直播预热积累订单。该产品在618期间成为类目TOP3,单月销售额突破2000万元,带动品牌整体GMV增长35%。这一成功表明,选品时效性与运营节奏的精准匹配能够放大趋势红利,甚至重塑市场格局。

3. 时效偏差引发的资源错配
某母婴品牌在2021年选品时误判市场需求,将夏季凉席作为6月主推品,但实际消费者因物流延迟更倾向购买即时到货的防晒用品。凉席库存积压导致仓储成本上升,而防晒用品因备货不足频繁断货,用户投诉率激增22%。运营团队不得不紧急调配预算清理凉席库存,同时追加防晒产品订单,但整体利润率仍被拉低8%。该案例说明,选品时效性偏差会直接引发供应链、营销和库存管理的连锁反应,导致资源严重错配。
十、两款工具在数据准确性与实时性上的平衡
1. 数据采集层:ETL与CDC的取舍
数据准确性与实时性的矛盾首先源于底层采集机制的设计差异。传统ETL工具采用批处理模式,通过定时调度(如每日T+1)抽取全量或增量数据,其优势在于可对源数据进行深度清洗、转换和校验,确保入库数据的准确性与完整性。例如,金融机构的监管报表通常依赖ETL工具,通过多轮数据比对与修正确保万无一失。然而,这种模式天然存在时效性短板,数据延迟从数小时到数日不等,无法满足实时风控、动态定价等场景需求。与之相对,CDC(变更数据捕获)工具通过监听数据库日志实时捕获增量操作,可将数据延迟压缩至秒级甚至毫秒级。例如,电商平台的库存同步系统依赖CDC工具,确保线上线下库存数据的实时一致。但CDC的局限性在于其仅能捕获数据变更,缺失对源系统的深度校验能力,若源系统存在脏数据(如格式错误或逻辑矛盾),这些缺陷会直接流入下游,在牺牲部分准确性的前提下换取实时性。

2. 数据处理层:批处理与流计算的权衡
在数据处理环节,批处理引擎(如Hadoop MapReduce)与流计算引擎(如Flink)的博弈进一步凸显了平衡难题。批处理以"有界数据集"为处理对象,可通过全量排序、去重、关联等复杂操作保证结果准确性,其典型的应用场景包括用户画像月度更新、财务结算等。但批处理的高延迟(通常小时级)使其难以应对实时决策需求。流计算引擎以"无界数据流"为处理对象,通过滑动窗口、状态管理等技术实现毫秒级响应,支撑着实时推荐、异常检测等场景。然而,流计算的实时性往往以数据近似为代价——例如,采用近似算法(如HyperLogLog)计算UV,或基于窗口聚合而非全量数据生成指标,这种"实时但不精确"的特性使其无法替代批处理在审计、合规等领域的核心地位。实践中,企业常采用Lambda架构,同时维护批处理与流计算两套引擎,通过批处理结果定期修正流计算结果,但系统复杂度的提升又会带来新的维护成本。
3. 数据服务层:缓存一致性与查询延迟的博弈
数据服务层面临缓存加速与数据强一致性的冲突。为提升查询性能,企业普遍在数据库与用户之间部署多层缓存(如Redis),将热点数据预加载至内存,使查询响应时间从秒级降至毫秒级。例如,短视频平台的推荐接口依赖缓存机制,支撑每秒万级的并发请求。但缓存的存在天然导致数据滞后——当源数据更新时,缓存需通过失效或更新策略同步,若采用"最终一致性"模型(如设置TTL过期时间),缓存与源数据库之间可能存在分钟级的数据不一致,这对金融交易、库存扣减等强一致性场景是不可接受的。反之,若采用"读穿"或"写穿"模式强制缓存实时更新,查询延迟会因频繁的数据库交互而显著增加。部分系统引入分布式一致性协议(如Raft)在缓存层实现强一致性,但性能损耗往往使其仅适用于低并发场景。如何在缓存加速与数据一致性间寻找平衡点,成为数据服务层架构设计的核心挑战。
十一、TikTok 算法更新下数据工具的响应速度
TikTok 算法的频繁迭代,已成为品牌和创作者运营策略中的最大变量。每一次核心参数的调整,都直接影响内容分发逻辑与流量池结构。在此背景下,数据工具的响应速度不再是单纯的性能指标,而是决定能否抓住流量窗口、实现快速迭代的核心竞争力。工具的响应滞后,意味着决策基于过时信息,最终导致资源错配与机会流失。
1. 算法瞬时性与数据延迟的矛盾
TikTok 算法的核心特征之一是其“瞬时性”。新发布的视频会在数小时内接受系统严格的初始流量测试,并根据用户互动数据(完播率、点赞、评论、分享等)决定是否进入更大的流量池。这个黄金决策窗口期极短,通常在24小时内。然而,传统数据分析工具普遍存在数小时甚至更长的数据延迟,当运营者看到数据报告时,内容已经完成了其主要的生命周期。这种滞后性导致运营者无法对爆款苗头进行即时加追(如追加DOU+投放),也无法对表现不佳的内容进行及时调整,从而错失了利用算法反馈进行快速优化的最佳时机。
2. 实时响应能力:工具核心竞争力
面对算法的快速变化,数据工具的价值正从“事后复盘”转向“实时干预”。一个具备高响应速度的工具,能提供分钟级的数据更新,让运营者近乎实时地监控视频的各项关键指标。例如,通过实时数据流,可以观察到某视频在特定时间段内的点赞率突然飙升,这可能预示着其触达了新的兴趣圈层。基于此,运营团队能立即调整文案、评论区互动策略,甚至快速制作同类型内容,以最大化利用算法推荐的势头。这种“边跑边看、边看边调”的敏捷运营模式,完全依赖于数据工具的实时响应能力,它将数据分析从静态参考变成了动态决策引擎。

3. 技术架构:支撑速度的关键底座
数据工具的响应速度并非偶然,其背后是强大的技术架构在支撑。首先,需要与TikTok官方API建立高效、稳定的数据通道,确保数据抓取的低延迟和高吞吐量。其次,后端处理系统必须具备强大的分布式计算能力,能够对海量涌入的原始数据进行快速清洗、聚合与计算。这通常依赖于流式处理框架(如Flink、Kafka)替代传统的批处理模式,实现数据“来一条,处理一条”。最后,前端可视化界面的优化也至关重要,通过缓存策略、异步加载和数据预计算,确保用户在查询和交互时能获得秒级反馈。对于用户而言,选择一个在数据更新频率、API稳定性和系统性能上经过严苛考验的工具,是在TikTok算法浪潮中保持领先的必要投资。
十二、选型建议:根据实时性需求选择工具的策略
1. 严苛实时场景:低延迟与高吞吐的平衡
在金融交易、工业控制或在线协作等场景中,数据处理的延迟需控制在毫秒级,且系统必须支持高并发。此时应选择原生支持流式处理的引擎,如Apache Flink或Kafka Streams。Flink凭借其事件时间处理和精确一次(Exactly-Once)语义,能有效应对乱序数据,适合对数据一致性要求极高的场景。而Kafka Streams则与Kafka生态深度集成,适合轻量级流处理任务。若涉及分布式事务,可考虑使用Pulsar或RabbitMQ的事务消息机制,确保数据投递的可靠性。此类工具通常牺牲部分灵活性以换取性能,需配合资源隔离(如Kubernetes)和硬件优化(如RDMA网络)进一步压榨极限。

2. 中等实时场景:灵活性与成本的最优解
对于用户行为分析、监控告警或实时仪表盘等场景,延迟容忍度在秒级到分钟级之间。此时可选择Lambda/Kappa架构,结合批处理与流处理工具。例如,使用Spark Streaming或Flink处理实时数据,同时依赖Hive或ClickHouse进行历史数据查询。若团队技术栈偏向云原生,AWS Lambda/Kinesis或Google Dataflow能显著降低运维成本。此类场景需权衡窗口策略(滑动窗口 vs 会话窗口)和状态管理方式,避免因数据倾斜导致性能劣化。对于中小规模业务,轻量级工具如Upsolver或Materialize可能更合适,其SQL接口可降低开发门槛。
3. 准实时场景:简化架构与易用性优先
在报表生成、数据同步或ETL调度等场景中,分钟级或小时级的延迟已能满足需求。此时应优先选择批处理工具(如Apache Spark、DolphinScheduler)或数据库内置功能(如PostgreSQL的Logical Decoding)。若数据源为API,可使用Airbyte或Fivetran等工具定时同步,并通过dbt进行数据转换。此类场景的核心是简化数据管道,减少依赖组件。例如,使用ClickHouse的物化视图替代独立的流处理任务,或借助StarRocks的Broker功能直接读取外部数据,避免冗余的中间层。需注意,工具选择应与下游消费方式匹配,如BI工具直连OLAP引擎时,需确保其支持并发查询和缓存策略。





