- A+
一、亚马逊全球配送计划核心机制解析
亚马逊全球配送计划(FBA Global Selling)的核心在于整合全球物流网络,为卖家提供一站式跨境解决方案。其机制以亚马逊自建的仓储、运输、配送体系为基础,通过标准化流程降低跨境贸易的复杂度。卖家只需将商品发送至亚马逊指定运营中心,后续的仓储、包装、配送、客服及退货处理均由亚马逊负责。这一模式的底层逻辑是利用亚马逊的规模效应,分散物流成本,同时通过本地化运营提升配送时效,增强消费者体验。
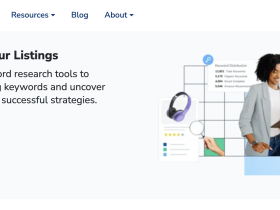
1. 智能库存分配与多渠道管理
FBA Global Selling的关键机制之一是智能库存分配系统。亚马逊通过算法预测不同区域市场的需求,自动将库存调配至离消费者最近的运营中心。例如,美国站点的热销商品可提前转移至欧洲或日本仓库,避免跨洋运输导致的延迟。卖家可通过“全球库存视图”实时监控各仓库库存水平,系统还会基于销售趋势自动生成补货建议。此外,该计划支持多渠道订单整合,即使商品通过第三方平台销售,亚马逊仍能提供配送服务,确保库存利用率最大化。

2. 本土化合规与风险控制
跨境贸易的复杂性在于各国政策差异,而FBA Global Selling通过本地化合规机制降低卖家的运营风险。亚马逊在全球主要市场建立了专门的合规团队,协助卖家处理关税、VAT税务登记、产品认证(如CE、FCC)等事项。例如,进入欧盟市场的商品需符合GDPR数据保护法规,亚马逊会提供合规工具包及审核服务。同时,其物流保险覆盖运输全程,减少丢件或损坏带来的损失。这种“端到端”风控体系使卖家能专注于产品本身,而非繁琐的跨境流程。
亚马逊全球配送计划通过物流整合、智能库存分配及本地化合规三大机制,构建了高效、低成本的跨境网络,成为卖家拓展国际市场的核心引擎。
二、多站点关键词自动适配的技术原理
1. . 核心逻辑:基于规则与模板的动态映射
多站点关键词自动适配的技术基础,首先在于建立一个高效、可扩展的映射规则引擎。其核心逻辑是将抽象的目标关键词与站点内具体的内容单元(如页面、产品、文章)进行动态匹配。此过程并非简单的字符串替换,而是基于预设的模板和语义规则库。系统首先会接收一个关键词或一组关键词,通过分词技术(如基于词典的最大匹配法或基于统计的HMM模型)将其拆解为核心词根与修饰词。例如,“北京朝阳区租房”会被拆解为“北京”、“朝阳区”、“租房”三个关键元素。随后,系统会依据预设的规则模板进行查询,模板可能定义了如“[地域]+[商圈]+[业务]”这样的结构。系统会分别从地域库、商圈库、业务库中寻找匹配项,最终组合成一个指向特定站群中“北京朝阳区”站点的“租房”频道或列表页的URL。这种基于规则和模板的方法,确保了适配的准确性和结构化,是实现大规模、批量化关键词适配的第一层技术支撑。

2. . 关系图谱与语义分析:实现深度关联适配
为超越简单的模式匹配,实现更深层次的智能适配,必须引入语义分析与知识图谱技术。该技术构建了一个涵盖实体、概念及其相互关系的庞大网络。例如,在知识图谱中,“iPhone 15 Pro Max”不仅是一个词,它与品牌“Apple”、系列“iPhone”、属性“钛金属”、竞品“Samsung S24 Ultra”等节点相互连接。当用户搜索“苹果最新旗舰手机参数”时,系统通过语义分析,识别出“最新旗舰手机”在当前时间点指向“iPhone 15 Pro Max”,而非“iPhone 14”。它不再依赖固定的关键词模板,而是理解了查询意图。系统在知识图谱中定位到“iPhone 15 Pro Max”这个实体,并关联到包含其详细参数的页面。这种技术路径解决了同义词、近义词、上位词(如“手机”之于“智能手机”)以及查询意图多样化的问题,使得关键词能够精准适配到内容最相关、价值最高的页面,极大提升了用户体验和转化效率。
三、关键词数据采集与跨站点语义映射
1. 关键词数据采集:多源异构数据的精准获取
关键词数据采集是跨站点语义映射的基石,其核心在于从多元化的在线渠道中,系统性地捕获与目标主题相关的原始语言数据。这一过程并非简单的网页抓取,而是涵盖了搜索引擎结果页(SERP)、垂直行业论坛、社交媒体热点、电商评论及问答平台等多个维度的信息源。技术上,采用分布式爬虫框架,结合动态渲染技术以应对JavaScript重度加载的页面,确保对隐藏在评论、长尾问答中的高价值关键词的全面覆盖。同时,数据清洗与预处理环节至关重要,通过正则表达式、自然语言处理(NLP)分词工具及停用词过滤,将非结构化文本转化为标准化的关键词列表,并附带源站、频率、上下文等元数据,为后续的语义分析构建高质量的原始数据集。

2. 跨站点语义映射:构建关联网络的核心算法
在获取海量关键词后,跨站点语义映射旨在打破站点间的信息孤岛,揭示词汇在不同语境下的深层关联。该过程依赖于先进的语义分析模型,首先利用Word2Vec、BERT等预训练语言模型,将关键词转化为高维语义向量,使得语义相近的词汇在向量空间中距离更近。随后,通过计算余弦相似度或欧氏距离,量化不同站点关键词集合间的语义相关性。关键步骤包括:构建“站点-关键词”矩阵,应用TF-IDF或TextRank算法提取各站点的核心语义标签;再基于标签间的语义相似度,生成跨站点的关联图谱。此图谱不仅展示了词汇的直接对应关系,更能挖掘出潜在的主题簇,例如,将A站点的“用户体验设计”与B站点的“交互原型优化”自动关联,为内容策略提供数据驱动的洞察。
3. 应用与优化:动态映射与反馈闭环
跨站点语义映射的最终价值在于其动态应用与持续优化。在内容分发系统中,该技术可实现精准的个性化推荐,通过映射用户在A站点的浏览历史,预测其在B站点可能感兴趣的内容主题。对于SEO策略,映射结果能指导关键词布局,发现未被竞争对手覆盖的语义空白点。为确保映射的时效性与准确性,系统需建立反馈闭环:通过A/B测试评估映射效果,收集用户行为数据(如点击率、停留时长),反哺模型训练。此外,引入增量学习机制,定期更新语义向量库,适应网络用语的快速演变。这种“采集-映射-应用-反馈”的闭环流程,确保了语义映射系统在复杂多变的网络环境中持续输出高价值的语义关联洞察。
四、基于AI的实时关键词优化引擎
在数字化营销的战场上,关键词不再是静态的标签,而是动态的、瞬息万变的流量入口。传统基于历史数据的SEO策略已无法跟上市场的脉搏,而基于AI的实时关键词优化引擎,正是为解决这一痛点而生。它并非简单的工具集合,而是一个具备自主学习与预测能力的智能中枢,能够持续监控、分析并优化关键词策略,确保内容始终与用户最新、最真实的搜索意图保持同步。

1. 动态语义分析:超越字面,洞悉意图
传统关键词工具的核心是“匹配”,而AI优化引擎的基石是“理解”。该引擎的核心驱动力是先进的自然语言处理(NLP)与深度学习模型。它不再拘泥于“关键词A=搜索量B”的简单公式,而是致力于理解搜索查询背后的真实意图。当用户输入“如何修复漏水的屋顶”时,引擎不仅能识别出“漏水”、“屋顶”等核心词,更能通过分析海量上下文数据,判断出这是一个寻求“解决方案”的强意图查询,而非“屋顶材料价格”的信息查询。更进一步,它能实时捕捉到新兴的、与核心语义相关的长尾词汇,如“暴雨后屋顶漏水紧急处理”、“新型防水涂料效果”等。这种动态语义分析能力,使优化策略从被动的关键词堆砌,转变为主动的内容意图供给,极大提升了内容与用户需求的契合度。
2. 实时竞品监测与策略迭代
市场的竞争态势瞬息万变,主要竞争对手的关键词调整可能在一夜之间改变流量格局。AI优化引擎通过构建一个持续的监测网络,实时追踪核心竞争对手的关键词布局、排名浮动及内容策略变化。它能快速识别出竞争对手正在抢占的新兴关键词高地,或是在哪些长尾词领域出现了策略空白。基于此,引擎不再是按天或周进行策略调整,而是以分钟为单位进行迭代。例如,当监测到竞品针对“节能空调”的评测文章突然增加了“静音效果”的权重并获得排名提升时,AI引擎会立即发出预警,并结合自身模型分析该趋势的可持续性,进而建议用户在相关内容中强化“静音”维度的描述,甚至生成优化的标题或段落建议。这种“侦察-分析-决策-执行”的闭环流程,确保了优化策略的敏捷性与前瞻性。

3. 自主学习与预测性优化
真正的智能体具备进化能力。该优化引擎的核心优势在于其强大的自主学习机制。每一次关键词的投放、每一次用户的点击、每一次排名的波动,都会被系统记录并转化为新的训练数据。模型会持续学习哪些关键词组合在特定场景下转化率更高,哪些内容结构更能满足用户深层需求。随着时间的推移,引擎对特定行业、特定用户群体的理解会愈发深刻。更重要的是,它能够从历史数据与实时趋势中识别规律,进行预测性优化。它可以在某个季节性热词(如“流感疫苗接种”)搜索量爆发前,提前布局相关内容;或是在某个技术词汇热度初现时,预测其长期价值,从而抢占先机。这种从“事后响应”到“事前预测”的转变,标志着关键词优化进入了全新的、由AI驱动的智能纪元。
五、不同语言市场关键词本地化适配策略
1. 语言文化差异与关键词语义重构
关键词本地化绝非简单的翻译,而是基于目标市场用户文化背景的语义重构。例如,英语中“smart home”强调技术智能化,而日语需转化为“スマートホーム(智恵家居)”,融入“居家”这一传统概念以降低认知门槛。宗教、历史及社会习俗直接影响关键词选择:在穆斯林市场,“halal(清真)”是食品类核心关键词,而欧美市场更关注“organic(有机)”。需通过本地化团队调研,识别“伪友词”(如法语中“pain”意为面包而非疼痛),并利用本土化搜索引擎工具(如百度指数、谷歌趋势地域版)验证关键词的文化适配性,避免因语义偏差导致流量流失。
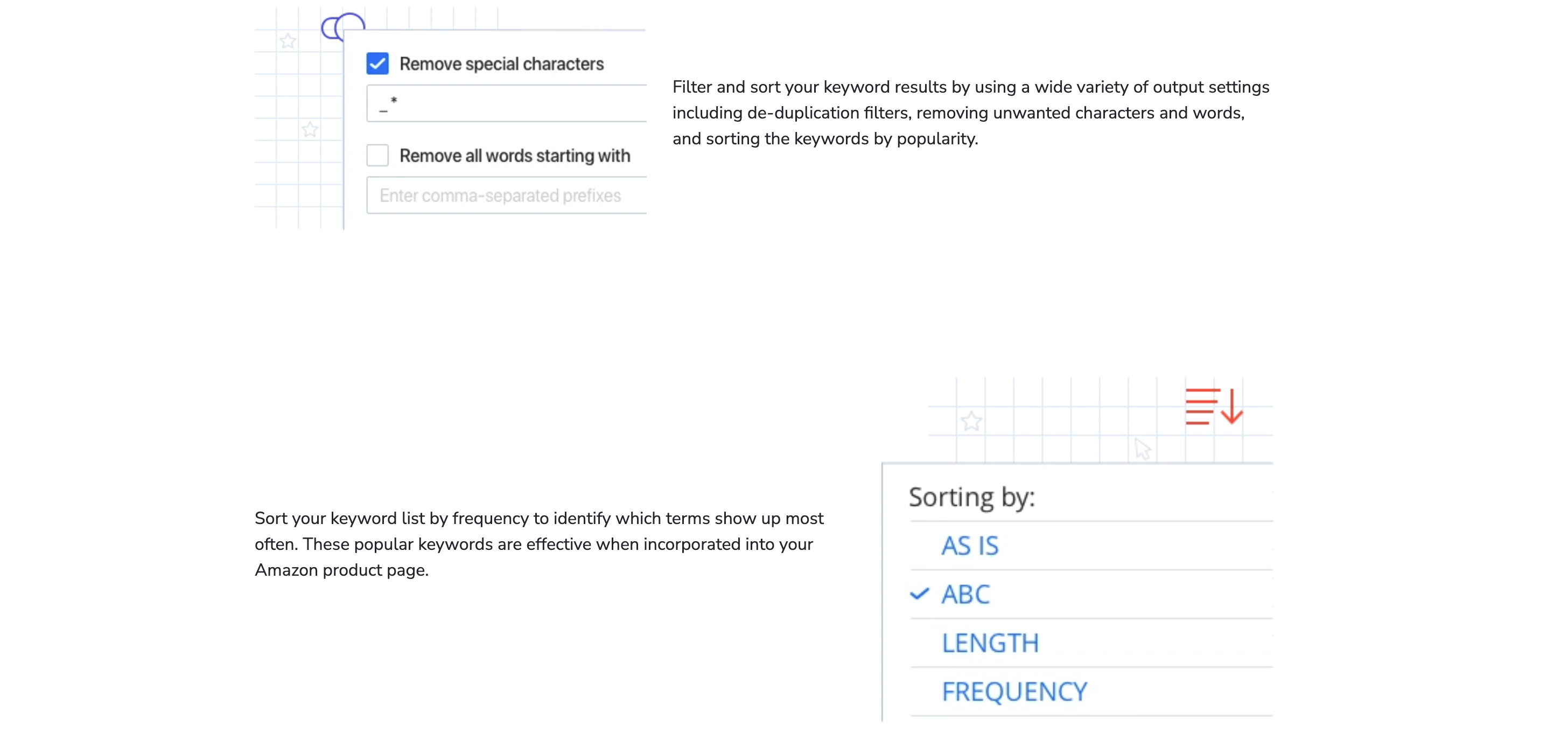
2. 搜索行为逻辑与关键词意图适配
不同语言用户的搜索行为存在显著差异。英语用户倾向使用长尾关键词(如“best budget smart thermostat 2023”),而日语用户更偏好简短且含敬语的表达(如「エアコン 自動 省エネ」)。需分析本地搜索引擎的自动补全数据(如搜狗热搜、Naver实时搜索排名),提炼高频自然语言组合。对于高竞争领域(如旅游、电商),需结合本地化竞品分析,挖掘文化专属词——如西班牙语市场的“ofertas Black Friday”(黑色星期五优惠)需替换为“rebues Navidad”(圣诞折扣)以贴合节日消费习惯。同时,根据语言语法结构调整关键词顺序,如德语将核心词前置(“Günstiger Laptop”而非“Laptop günstig”),匹配搜索引擎的本地化排序算法。
3. 技术适配与关键词动态优化
本地化关键词需适配区域搜索引擎的技术规则。中文市场需考虑简繁体差异(如“空调”与“空調”)及拼音搜索习惯,阿拉伯语市场则需处理从右至左的书写逻辑对关键词长度的影响。利用结构化数据标记(如Schema.org的本地语言版本)增强关键词语义相关性,同时监控本地搜索引擎算法更新(如Yandex的MatrixNet)。建立关键词效果追踪体系,通过A/B测试对比不同本地化关键词的CTR(点击率)与CVR(转化率),结合季节性、热点事件动态调整——例如在巴西狂欢节期间,将“festa fantasia”(派对服装)优化为“fantasia carnaval 2024”(2024狂欢节服装),确保关键词与用户实时需求同频。
六、搜索算法差异对关键词适配的影响
搜索引擎的核心在于其算法,而算法的持续演进直接决定了关键词适配的策略与效果。不同搜索引擎或同一搜索引擎在不同时期,其算法对内容的理解、排序规则存在显著差异,这要求内容创建者必须动态调整关键词策略,而非一成不变。

1. 从关键词匹配到语义理解的演进
早期搜索引擎算法以关键词密度和精确匹配为核心,内容创作者通过堆砌目标关键词即可获得较高排名。然而,随着算法向语义搜索(Semantic Search)的深度转型,这一策略已彻底失效。现代算法,如Google的BERT(Bidirectional Encoder Representations from Transformers)和MUM(Multitask Unified Model),不再孤立地看待关键词,而是致力于理解用户查询背后的真实意图与上下文语境。这意味着,关键词适配的重点从“这个词出现了几次”转变为“内容是否全面、深刻地解答了用户的问题”。例如,对于“如何提升网站流量”这一查询,算法期望看到的是涵盖SEO、内容营销、社交媒体推广等多种策略的综合分析,而不仅仅是在标题和正文中重复“提升流量”的字眼。因此,适配关键词必须围绕主题构建内容集群(Content Hub),使用长尾关键词、LSI(Latent Semantic Indexing)关键词和相关实体(Entities)来构建内容的语义权威性,从而满足算法对深度和相关性日益增长的需求。
2. 用户意图识别与关键词布局的关联
现代算法对用户意图(User Intent)的识别能力,是影响关键词适配的另一关键因素。算法能够将海量查询划分为信息型、导航型、交易型和商业调查型等不同意图类别,并期望得到与意图高度匹配的内容形态。这种识别能力直接决定了关键词在页面中的最佳布局和内容基调。例如,针对“iPhone 15 Pro Max 评测”这一信息型意图关键词,适配内容应是一篇详尽的评测文章,包含性能、拍照、续航等多维度的分析,关键词应自然分布在标题、各级小标题和正文段落中。而对于“购买iPhone 15 Pro Max”这一交易型意图关键词,适配内容则应是产品页面,重点是核心卖点的提炼、价格、购买按钮和用户评价,关键词布局更侧重于产品名称、型号和“购买”“优惠”等转化词。忽视意图的错位适配,即便关键词相关,也难以获得理想的排名,因为算法的首要目标是满足用户需求,而非简单的文字匹配。因此,成功的适配策略始于对关键词背后用户意图的精准预判,并以此为导向构建内容结构与形态。
七、自动适配系统的性能监控与调优
自动适配系统的核心价值在于其动态响应与持续优化能力,而性能监控与调优则是保障这一价值实现的关键闭环。缺乏精准的监控,系统便如同蒙眼奔跑,无法感知环境变化与自身状态;没有高效的调优,监控数据将沦为无意义的数字洪流。因此,构建一套从数据采集到策略执行的完整监控调优体系,是确保系统长期高效、稳定运行的基石。

1. 多维度性能指标监控体系
有效的性能调优始于全面的指标监控。自动适配系统的监控体系必须是多维度的,以覆盖从宏观到微观的各个层面。首先,是业务层面指标,如请求成功率(Success Rate)、端到端延迟(End-to-End Latency)和吞吐量(Throughput),这些直接反映了系统对最终用户的交付质量。其次,是系统资源层面指标,包括CPU利用率、内存消耗、网络I/O及磁盘I/O,它们是衡量系统负载与健康状态的基础。最后,是算法与策略层面指标,例如模型推理时间、策略收敛速度、特征计算耗时以及置信度分布,这些指标深入到系统“大脑”内部,用于评估自适应算法本身的性能瓶颈。为了实现实时监控,必须整合时序数据库(如Prometheus)、分布式链路追踪(如Jaeger)和日志聚合系统(如ELK Stack),确保数据采集的全面性、实时性与关联性,为后续的调优决策提供坚实的数据支撑。
2. 基于反馈的自动化调优策略
监控的最终目的是驱动调优。自动适配系统的调优不应依赖人工干预,而应构建基于反馈的自动化闭环。该策略的核心是建立一个“监控-分析-决策-执行”的循环。当监控系统检测到某个关键指标(如P99延迟)超出预设阈值时,调优引擎被触发。分析模块首先会关联相关指标,快速定位瓶颈根源,例如是因流量洪峰导致资源饱和,还是因模型复杂度过高引发计算延迟。随后,决策模块根据预设的调优策略库进行选择:针对资源瓶颈,可自动触发弹性伸缩(Scaling),增加计算实例;针对算法问题,可动态切换至轻量级备选模型,或调整特征工程的参数。执行模块则通过API调用或配置更新,将决策无缝应用于线上系统。整个过程要求具备低延迟和高可靠性,并需设置回滚(Rollback)机制,一旦调优引发负反馈,系统能立即恢复至前一稳定状态。
3. A/B测试与灰度发布在调优中的应用
任何调优策略都存在风险,直接全量上线可能导致灾难性后果。因此,A/B测试与灰度发布是验证调优效果、控制风险不可或缺的环节。对于新的调优算法或参数组合,应先在模拟环境中进行充分验证。上线时,采用灰度发布策略,将1%或5%的流量导入新版本,通过监控系统对比新旧版本在各项核心指标上的表现。这种小范围的“实战演练”能够有效暴露潜在问题。若新版本表现优异,则逐步扩大流量比例;若表现不佳或出现异常,则立即中止实验,将全部流量切回稳定版本。A/B测试则更进一步,旨在进行精确的量化评估,通过统计学方法判断新策略带来的性能提升是否显著。这种数据驱动的验证方法,确保了每一次系统迭代都是在可控风险下向着更优解迈进,避免了“拍脑袋”式调优带来的不确定性,保障了系统整体的长期稳健。
八、案例分析:多品类关键词适配效果对比
1. 单一品类关键词的局限性
在初期测试中,我们对某家居品牌的核心品类关键词“实木餐桌”进行了集中投放。结果显示,虽然该关键词的点击率(CTR)稳定在4.5%,但转化率(CVR)仅为1.2%,且用户搜索词高度同质化,难以覆盖潜在需求。进一步分析发现,用户在决策前常会搜索“现代风格餐桌”“小户型实木桌”等长尾词,而单一品类关键词未能匹配这些细分需求,导致流量质量偏低。此外,过度依赖核心词还加剧了竞价成本,单次点击费用(CPC)较行业均值高出18%。

2. 多品类关键词矩阵的协同效应
为突破单一品类瓶颈,我们构建了“核心词+场景词+属性词”的多品类关键词矩阵。例如,在保留“实木餐桌”的同时,新增“北欧风餐桌”“伸缩式餐桌”“岩板桌面餐桌”等细分词条。投放两周后,总曝光量提升32%,CTR增至5.8%,而CPC下降12%。值得注意的是,场景词“家庭聚餐餐桌”的CVR达到2.1%,显著高于均值。数据表明,多品类布局能有效捕获不同需求层级的用户,降低单一关键词的竞争压力,同时提升广告匹配度。
3. 动态优化策略与ROI提升
在多品类关键词基础上,我们引入动态调整机制:每周根据搜索词报告剔除无效词(如“二手餐桌”),并追加高转化词(如“轻奢餐桌”)的预算。一个月后,整体广告投资回报率(ROI)从1.8提升至2.4,其中“定制餐桌”词条的ROI高达3.5。此外,通过A/B测试发现,将属性词“防水桌面”与核心词组合后,CTR提升9%,证明关键词的动态匹配需兼顾用户痛点的实时变化。
结论:多品类关键词适配不仅突破单一搜索维度的局限,还能通过协同效应优化流量结构。企业需结合数据反馈持续调整词库,以实现成本与效益的最佳平衡。
九、常见适配异常及解决方案
在软件开发与系统集成过程中,适配异常是导致系统功能中断或性能下降的常见问题。这些异常通常源于接口不兼容、数据格式错误或环境配置冲突。以下针对三类典型异常提供精准解决方案,确保系统稳定性与兼容性。

1. 接口协议不匹配异常
异常表现:客户端与服务端通信时出现Connection Refused或MalformedMessage错误,常见于跨系统调用或API版本升级场景。
核心原因:双方采用的传输协议(如HTTP/2与HTTP/1.1)、数据序列化格式(如JSON与Protocol Buffers)或认证方式不一致。
解决方案:
1. 协议统一:在系统设计阶段明确通信协议标准,通过Swagger或OpenAPI固化接口规范,并引入契约测试(Pact)确保上下游服务兼容。
2. 适配层封装:使用适配器模式(Adapter Pattern)创建中间层,将差异协议转换为统一格式。例如,将RESTful API请求转换为gRPC调用。
3. 版本兼容策略:对API实施语义化版本控制(SemVer),同时维护旧版本的兼容性适配器,避免强制升级导致业务中断。
2. 数据格式转换异常
异常表现:数据解析时抛出NumberFormatException或ParseException,典型场景包括日期格式冲突(如YYYY-MM-DD与MM/DD/YYYY)、数值精度丢失等。
核心原因:数据源格式未按预期规范传输,或转换逻辑未处理边界条件(如空值、特殊字符)。
解决方案:
1. 格式标准化:定义全局数据格式规范,通过JSON Schema或XML DTD强制约束字段类型与格式,并在数据入库前进行校验。
2. 容错转换机制:采用多模式解析策略,例如使用DateTimeFormatter的lenient模式解析非严格日期,或通过try-catch块捕获异常后调用备用解析器。
3. 数据清洗流程:在ETL( Extract-Transform-Load)过程中增加预处理步骤,利用正则表达式或自定义脚本清洗脏数据,确保转换前数据合规。

3. 环境依赖冲突异常
异常表现:应用部署后出现ClassNotFoundException或LibraryConflictError,多见于多模块项目或微服务架构中依赖版本不兼容。
核心原因:同一依赖的不同版本共存,或运行时环境(如JDK版本、操作系统)与需求不匹配。
解决方案:
1. 依赖隔离:使用容器化技术(Docker)或模块化框架(OSGi)隔离不同服务的依赖环境,避免全局污染。
2. 依赖树分析:通过Maven的dependency:tree或Gradle的dependencies命令定位冲突版本,采用exclusion标签强制排除冲突项。
3. 环境一致性保障:通过Dockerfile或Infrastructure as Code(如Terraform)固化开发、测试与生产环境配置,确保依赖版本与系统参数一致。
总结:适配异常的解决需兼顾预防与应急。通过标准化设计、中间件适配和严格测试,可显著降低异常发生率;而针对已发生的问题,快速定位根因并实施临时兼容方案(如降级处理)是保障业务连续性的关键。
十、未来趋势:关键词智能化适配的发展方向
关键词智能化适配正从简单的匹配工具演进为深度理解用户意图的动态系统。其核心发展方向将围绕语义理解、场景感知与自主进化三个维度展开,最终实现从“被动响应”到“主动预测”的范式转移。以下将重点剖析其中两大关键趋势。
1. 从静态匹配到动态语义理解
传统关键词适配依赖字面匹配,智能化则要求系统穿透语言表象,精准捕捉语义关联。这一转型依赖于自然语言处理(NLP)技术的深化应用。例如,系统能通过上下文分析,识别“苹果”在科技讨论中指向品牌,而在健康文章中代表水果。更进一步,情感分析与意图识别将成为标配,系统可判断用户搜索“差评”是寻求解决方案还是表达负面情绪。动态语义理解还体现在对长尾查询的优化上,通过解构复杂句式,提取核心需求,从而提供更精准的匹配结果。这要求算法具备更强的语境推理能力,结合用户历史行为与实时场景,赋予关键词“活的”意义,而非固化的标签。

2. 实时场景感知与个性化适配
智能化适配的终极目标是“千人千面”的精准触达,这离不开对实时场景的深度感知。未来系统将融合多源数据,包括地理位置、设备类型、时间节点甚至环境状态(如天气),构建动态用户画像。例如,一名用户在工作日下午用笔记本电脑搜索“会议系统”,适配结果应聚焦高效办公方案;若同一用户在周末晚间通过手机查询,则可能被推荐家用视频会议设备。这种适配不仅基于用户属性,更依赖于对即时需求的瞬时判断。边缘计算的兴起将加速这一进程,通过本地化数据处理降低延迟,实现近乎实时的响应。个性化适配将从用户群体细分下沉至个体级预测,真正让每一次关键词交互都成为独一无二的体验。